グランドチャレンジデータ公開用ページ
このページは,NIIグランドチャレンジ「情報環境を支える日常的インタラクションデータ収録のためのプラットフォーム構築」(2009–2011)の研究成果を公開するためのページです.
人々のインタラクション研究のための収録ノウハウの掲載と,サンプルデータの配布を目的とします.
Table of Contents
1 プロジェクト概要
1.1 名称
NIIグランドチャレンジ「情報環境を支える日常的インタラクションデータ収録のためのプラットフォーム構築」(2009–2011)
1.2 目的
本課題ではデータ収録における個人情報の保護とプライバシーの侵害の問題と,日常的インタラクションデータの豊かさと多様性の維持を統一的に検討するべき課題と位置づけ,日常的インタラクションデータ収録のためのプラットフォーム構築を目指す.これまで個々のプロジェクトが独自の手法で回避してきた個人情報に関する問題に対する統一的手法を確保した上で,日常的なインタラクションデータを収録・集積するためのモデルケースとなる手法を構築する.そして,それを広く公開することで日常的インタラクションデータ収録・集積のためのガイドラインを整備する.
1.3 データ概要
現在配布可能なデータは以下です.
1.3.1 アニメ再生課題データ
3人の実験参加者のうち2人に同じアニメを見てもらい,協力してもう一人の実験参加者に説明する課題です.
使用したアニメはジェスチャー研究でよく用いられているCanary Row(リンク先YouTube)を使用しました.
以下のデータを有しています.
- 発話書き起しデータ
- 話者ごとの音声データ
- 話者正面の映像データ(無音)
- 3人の話者の俯瞰映像データ(無音)
- ジェスチャーアノテーションデータ(注釈ソフトELANの形式)
- モーションキャプチャーデータ
- アイマークレコーダーデータ
1.4 メンバー
- 坊農真弓(国立情報学研究所)
- 古山宣洋(国立情報学研究所)
- 板橋秀一(国立情報学研究所)
- 大須賀智子(国立情報学研究所)
- 山川仁子(国立情報学研究所)
- 市川熹(早稲田大学)
- 井上雅史(山形大学)
- 榎本美香(東京工科大学)
- 小磯花絵(国立国語研究所)
- 菊池英明(早稲田大学)
- 角康之(はこだて未来大学)
- 高梨克也(京都大学)
- 伝康晴(千葉大学)
- 花田里欧子(京都教育大学)
- 細馬宏通(滋賀県立大学)
- 前川喜久雄(国立国語研究所)
2 データの入手方法
本データは,国立情報学研究所 IDR事務局 より提供致します。現在データの準備中につき,配布開始までしばらくお待ち下さい。
3 インタラクション研究のための収録から分析までのノウハウ集
ここでは,マルチモーダルなインタラクション研究を行うにあたって,データの収録から分析までの手続きを公開します.
これまでの収録での試行錯誤の結果から収録を行う際のノウハウや,分析事例を順次掲載致します.
3.1 手続きの概略
人々のインタラクションの研究手続きには,大きく分けて2つの段階があります(下図).
1つ目は,収録から分析を行える状態までデータを加工する段階,つまりコーパスを策定する段階です(下図の緑部).
2つ目は,データを使って実際に分析する段階です(下図の青部).
これらの2つの段階のうち,特に「データ加工」と青部の分析の段階は短い双方向の矢印で結ばれています.これは,分析を行うために必要なアノテーションが生じ,そのアノテーション作業を行うことがあることを意味します.
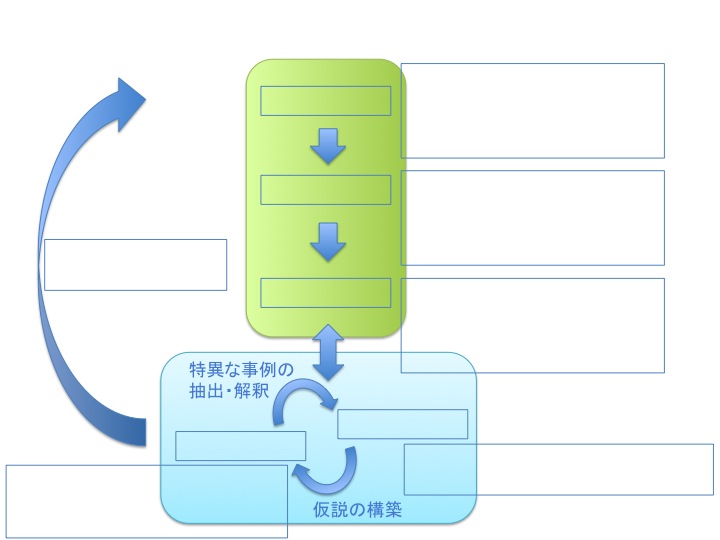
- 収録目的の明確化
- 収録のための仕様策定
- 実験参加者オーディション
- より詳細は 3.2 収録準備 へ
- 参加同意書とアンケート
- 参与者へ実験器具の装着
- 参与者とカメラの配置
- より詳細は 3.3 データ収録 へ
- 分析対象の現象を決定
- アノテーションマニュアル作成
- アノテーション実施
- より詳細は 3.4 データ加工 へ
- 分析対象をアノテーションから抽出
- より詳細は 3.5 質的分析 へ
- 仮説の検証
- アノテーションからパターン抽出
- より詳細は 3.6 量的分析 へ
- 追加または新規の収録へ
3.2 収録準備
具体的な収録作業に入る前に,いくつか確認しておくべき事柄があります.
3.2.1 収録目的の明確化
収録目的を明確にしておくことは非常に重要です.どんな分析を行うためのデータ収録なのかが明確でないと,使用する機材,集める実験参加者,実験計画が定められません.
本データでは, 発話と身体動作の微細な調整を分析するためのコーパス構築が目的ですので,それぞれの参与者の細かな身体動作や発話もしっかり捉える必要があります.そのため,
- カメラは少なくとも上半身を全部捉えなければならない
- 身体動作のより客観的な指標としてアイマークレコーダーやモーションキャプチャーの使用も望ましい
- 身体動作が十分に産出されるように手すりのないイスを使用する
など,収録に必要なものが見えてきます.
3.2.2 収録のための計画書策定
収録目的にあわせた実験参加者の募集や,機材の手配のために収録当日の動きなどを計画書としてまとめておきます.
特に,本データのようにアイマークレコーダーなどの特殊な機材を使用する場合は,機材と実験参加者の相性があるため,募集する実験参加者について明確に指定しておく必要があります(コンタクトレンズを使用しない者など).
上の計画書のように当日使用する機材,募集する実験参加者,当日の流れ(人員配置,役割,タイムテーブル)を細かく文書化することは以下の2点で有用です.
- 共同研究者間での収録へのイメージを共有できる
- 収録を業者に発注する場合にそのまま提出できる
3.2.3 実験参加者オーディション
既に3.2.2 収録準備の計画書で求める実験参加者は規定していますが,実際に機材を装着してみないことにはその実験参加者が適当かどうか分からないものです.本データの収録にあたっては,事前に仕様書に沿って実験参加者の募集を行い,実験参加者をオーディションで選定致しました.選考基準は以下の2点です.
- 装着した機材との相性(ちゃんとデータが取得できるか)
- 受け答えがしっかりしているか(コミュニケーションがしっかりとれるか)
2点目に関しては,機材の装着時などに世間話を行い,そのときの印象を選定にもちいました.
3.3 データ収録
収録当日に行うべき事柄について述べていきます.
3.3.1 参加同意書,アンケート
実験参加者には収録の事前・事後にいくつかの書類を記入してもらう必要があります.特に参加同意書は必須のもので,本データでは以下の点について教示し,記入してもらいました.
- 研究目的
- 拘束時間
- 被る可能性のある不利益とその対処措置
- 研究への参加について
- 参加が強制的でないこと
- 参加の中断が可能なこと
- データの取り扱いやプライバシーについて(研究機関の倫理規定に目を通してもらいます)
また,必須ではないですが,研究を行う上でとっておくと良いものに事後アンケートがあります.例えば,本データの場合,特殊な機材をつけた上での会話となりますので,そのような機材が会話に与えた影響などの内観報告をとっておくことはデータを解釈するする上でも参考になります.また,次回の収録の際に気をつけるべきヒントなどが得られる可能性があるため,アンケートの実施をオススメします.まとめると,大まかに以下の点を確認できるようなアンケートを行うと良いと思います.
- 収録自体についてのアンケート(機材や教示,手続きなどの次回の収録に参考になる情報)
- 会話内容についてのアンケート(収録したデータを解釈する上で参考になる情報)
3.3.2 各参与者への実験器具・収録機材の取り付け
実験参加者の募集を業者に委託している場合,契約によっては機材の取り付け時間にも支払うべき謝金が発生します.そのため,機材と実験参加者との相性の確認を行うオーディション(3.2.3節参照)や,日頃から機材の扱いに習熟しておく等,実験参加者の負担軽減策を講じると良いでしょう.
本データの収録では,以下の機材を各実験参加者につけてもらいました.
- ワイヤレスマイク(各参与者の発話を別々に収録するため)
- モーションキャプチャー用のマーカ(下図のヘッドキャップ上の白い点.他にもベストを着てもらう)
- EMR: アイマークレコーダー (下図のヘッドキャップ)

EMRのとりつけ.実験参加者の視線を追えているかキャリブレーション中.ヘッドキャップのツバに実験参加者の視界を模しているメインカメラがある.ヘッドキャップから延びている棒の先に赤外線照射・受信機がついている.
3.3.3 参与者とカメラの配置
本研究のようにマルチモーダルなインタラクション研究のための収録で重要なのは,カメラの配置です.
まずそれぞれの参与者のほぼ全身を捉えるために正面にカメラを設置します(下図).ただこれだけだと他の参与者が同時に何をしているのか分かりづらいため,参与者全体を俯瞰的に捉えるカメラを何台か用意すると良いでしょう.
図では俯瞰的なカメラを1台しか描いていませんが,本データでは2台俯瞰用のカメラを使用しています.

参与者とカメラと機材の配置
また,参与者に収録であることを不必要に意識させないために,実験者は別室にて待機するなど参与者の視界に入らない方が良いでしょう.機材についても同様で,機材と接続しているPCなどはなるべく参与者の視界から外した方が良いと思われます.
本データ収録では,ロールカーテンで部屋を区切り,カーテンを隔てて機材などを隠しました.
3.3.4 収録開始時の同期とり
複数のカメラとマイクを活用するためには,収録開始時の同期とりがとても重要です.古くから映画などで用いられているものに「カチンコ」があります.

カチンコ
これは小さな拍子木のようなもので,拍子木が合わさって開くまでが1フレームになるように叩くそうです.この時のカチンコの音と,拍子木が合わさった瞬間のフレームを起点として,後でビデオファイルを合成したりします.
本データでは,カチンコではなく,以下のような装置を手作りして用いました.いずれにせよ,収録の開始には,カメラ-カメラ間,カメラ-マイク間で同期をとれるような合図を入れておくと良いでしょう.

同期とり用の装置.ピーという音と同時に発光する.この音と光を起点とする.
3.4 データ加工
収録したデータのうち映像や音声データは,基本的にはそのままでは分析を行えません.質的,量的分析のそれぞれに持っていきやすいようにデータを加工する必要があります.具体的には,以下の手順を踏むことになるでしょう.
- 分析対象の現象を明確化(無数に行われている行為の何に注目するのか,研究目的から明確にする)
- ターゲットの行為の定義を明確にする(アノテーションマニュアル作成)
- 実際にアノテーションを施す
以下では,それぞれについて説明を加えていきます.
3.4.1 分析対象の現象を明確化
本研究では,発話と身体動作(視線,身振りなど)がどのように調整されているかに注目しています.特にそれらのモダリティを,インタラクションの中でどのように調整しているかに注目しています.そのため,例えば「参与者間の視線配布がターンテーキングとどのように関連しているか」などを明らかにしたい場合,「誰が誰をいつから見始めたか」という情報があると便利です.
本研究の目的から,それぞれのモダリティに対して以下のような情報がわかるようにデータの加工を行えばよいと考えられます.
- 発話(1発話ごとへ分割)
- 話者
- 発話開始/終了時間
- 発話内容
- 視線
- 誰の視線か
- 誰への視線か
- 視線開始/終了時間
- ジェスチャー
- 誰のジェスチャーか
- 開始/終了時間
このように,研究目的を満足できるようなデータの形は何かを大まかにイメージします.
3.4.2 アノテーションマニュアル作成
ここではより具体的に,分析対象とする現象についての定義を与えていきます.例えば,発話を書き起すだけでも以下のような色々な問題を含んでいます.
- 発話の区切りはどう定義するか
- 表記はどのように行うか(漢字の使用はOKにするかどうか)
- どこまで記述するか(呼気音,吸気音,笑いなどはどのように扱うか)
このような問題はアノテーションを行っていく中で「これはどのように扱おう」と,直面して初めて気づくことがしばしばです.問題に直面するごとにマニュアルの見直しを行い,揺れのないアノテーション法を作りましょう.
本データには以下のマニュアルに沿ってアノテーションが施されています.
これらのアノテーションを行う上でのTipsとして,「分類に"その他"を用意しておくこと」が挙げられます.どうしても分類に迷う箇所はとりあえず「その他」として,悩んだ理由などをコメントしておきます.それをもとに共同研究者とマニュアルの見直しを行うと良いでしょう.
3.4.3 アノテーションの実施
アノテーションのツール( ELAN と Anvil について)
本データのアノテーションには注釈ソフト ELAN を用いています.多くのビデオフォーマットに対応し,動画を再生させながら注釈を行えます.吐き出せるデータフォーマットも多様で,タブ区切りフォーマットなど統計用ソフトと相性の良いデータ形式でアノテーション結果を吐き出すことが出来ます.非常に多機能なソフトウェアですので,ここで使用方法は述べませんが 滋賀県立大学の細馬宏通先生のサイト がとても参考になります.類似ソフトウェアに Anvil があります.最新のAnvilにはELANにはない機能があります.それはアノテーション間に参照関係を付与する機能です.例えば,聞き手のある「うなずき」が話者のどの発話に対してのものであったかという記述を,アノテーション間にリンクをはることで実現します.参照関係についてアノテーションをしたい場合はAnvilを使うと良いでしょう.このように,どのソフトウェアを利用するかは分析目的によりますので,使い分けてご利用ください.
アノテーターの人数について
アノテーションを実施する上で余裕があればやっておくべきことは,複数のアノテーターにアノテーションを行ってもらうことです.3人以上のアノテーターがいればそれぞれのアノテーションを付き合わせて(κ係数などを求めて),アノテーションの信頼性を定量的に求めることが出来ます.3.5 質的分析
アノテーションまで終了すれば,質的・量的分析の両方の分析に取りかかれます.以下では,本データを利用した方々の分析例を掲載させて頂きます.本データを入手された方で分析例としてご自身の成果を掲載させて頂ける方は 連絡先 までご連絡ください.
3.5.1 分析例: 協調語り場面のジェスチャーと発話の調整(東山,菊地,坊農)
この分析例はMiMI2011で発表したものです.草稿は こちら .