JSL Colloquial Corpus
Data Collection, Translation and Annotation Conventions ( Version 1.1 )
Table of Contents
Digital Content and Media Sciences Research Division, National Institute of Informarics, Japan 2-1-2 Hitotsubashi, Chiyoda-ku, Tokyo 101-8430
Contact : jsl-corpus-mem@nii.ac.jp
1 Acknowledgements
• Japan Society for the Promotion of Science (JSPS), M. Bono (PI), Y. Osugi, K. Kikuchi, Y. Horiuchi, and N. Harada, A Colloquial Corpus of Japanese Sign Language: The Growth of Linguistic Awareness between Deaf and Hearing, JSPS, Grants-in-Aid for Scientific Research, Category B, 2011-2014; Y. Osugi (PI), M. Bono, W. Takei, R. Kikusawa, Description, Documentation, and Analysis of Lexicon in Japanese Sign Language from Deaf Perspectives, JSPS, Grants-in-Aid for Scientific Research, Category B, 2013-2016; M. Bono (PI), Proposal for Linguistic Description System in Signed Interaction Analysis, JSPS, Grants-in-Aid for Young Scientist, Category A, 2014-2017.
• JSL Colloquial Corpus Project Participants and Collaborators from the deaf community in Gunma, Nara, Nagasaki, and Fukuoka for being involved in the JSL Colloquial Corpus Project.
• Japanese Federation of the Deaf.
• The National Research Association for Sign Language Interpretation (Zen-tsu-ken).
• Prof. Adam Schembri, La Trobe University.
• Prof. Robert Adam, University College London (UCL).
• Prof. Kearsy Cormier, University College London (UCL).
• BSL Corpus Project.
2 Introducition
This document describes the data collection, translation and annotation conventions used to build and share the JSP Colloquial Corpus. In addition, it presents our linguistic motivations toward sign language corpora by explaining several work procedures. We began building a corpus of Japanese Sign Language (JSL) in April 2011 with the support of the Japan Society pppfor the Promotion of Science. This is the first JSL corpus developed under the purpose of academic and public use.
In 2011, we invited the principal investigator (Prof. Adam Schembri) of the BSL corpus project at that time to Japan to help us create such a corpus. Our initial steps in building a JSL corpus were based on advice from him and his colleagues.
3 Data collection
This chapter consists of two sections:1) Area, participants and tasks, and 2) Procedures of dialogue tasks.
3.1 Area, participants and tasks
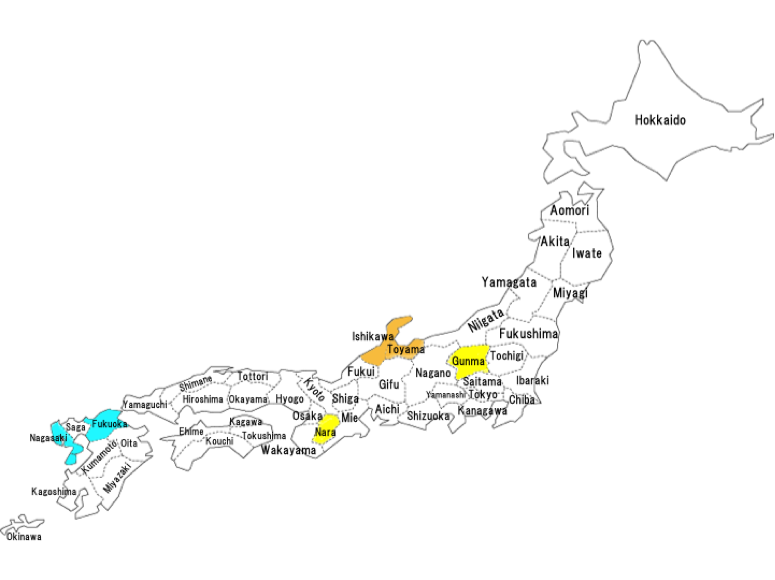
Figure 1: Regions and prefectures from which data were collected
The first stage of this project was funded as Category B, 1,911,000JPY (10,462GBP) (PI: M. Bono) from 2011-2014 by the Japan Society for the Promotion of Science (JSPS). From May to July 2012, we videoed 40 deaf subjects in two prefectures, Gunma and Nara (colored in yellow in Fig.1), each of the prefectures has one school for the deaf. We obtained data from an age-balanced sample of individuals aged 30–70 in each prefecture, and each age group was divided into same-sex pairs. Our participants from Gunma and Nara, were in their 30s, 40s, 50s, 60s and 70s, both male pairs and female pairs. We used three methods to collect data: interviews, in which field workers, assistants of native signers living in the same area, and who knew the procedures in advance, asked participants about their language life, environment and so on (for introductory purposes only, not open access); dialogues about animation, in this procedure, one participant memorized the story of "Canary Row," and explained it to other participants; and lexical elicitation, in which participants showed correspondent signs for 100 slides of pictures and words shown on a monitor .
3.2 Procedures for dialogue tasks
This section consists of six parts: 1) Devices and settings, 2)Synchronizing and cropping of multiple video clips, 3) Prefecture ID, 4) Participants’ ID, 5) Session ID, and 6) File names.
3.2.1 Devices and settings
We used three high-definition cameras, four lighting devices, blue panels, and blue chairs for the recordings (Fig.2 & Fig.3). During the dialogue task, camera A showed the two participants from the knees up; camera B focused on the participant on the left, also showing the back of the other participant; and camera C focused on the participant on the right, also showing the back of the other participant. The camera angles and spatial configuration were designed to enable spatial reproducibility in the service of annotating gaze direction and pointing during the dialogues. We added a sound cue made by a clapperboard to each file for timing synchronization later.
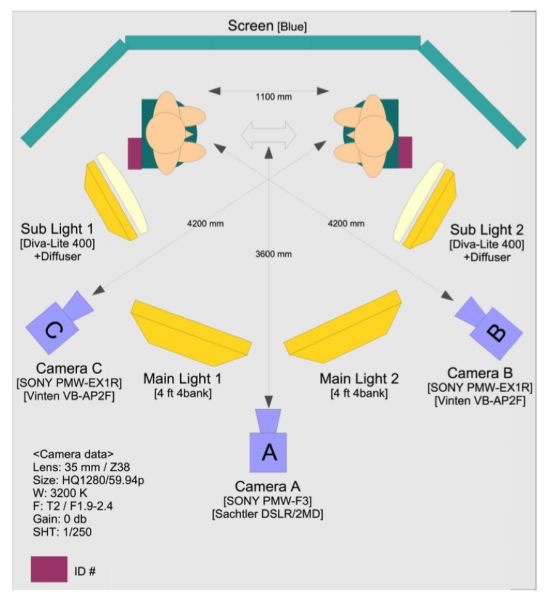
Figure 2: Camera and lighting setup
3.2.2 Synchronizing and cropping of multiple video clips

Figure 3: Two versions of the three camera angles used for data collection: Original (upper), Cropped (lower)
Three independent files are synchronized using Final Cut Pro. The original combined-angles image includes the interlocutor’s back recorded by cameras B and C; also there is dead space—showing as black areas. The cropped combined-angles image does not include the interlocutor’s back and there is no dead space. Video images from all camera angles were enlarged to make then easy to see for detail analysis. All clips were made available on our website.
| Region | Kanji | Romanized Alphabet | Abbr. | Localreregional Alphabet | Abbr. | |
|---|---|---|---|---|---|---|
| 1 | Hokkaido | 北海道 | Hokkaido | HK | ||
| 2 | Tohoku | 青森 | Aomori | AM | ||
| 3 | 岩手 | Iwate | IT | |||
| 4 | 宮城 | Miyagi | MG | |||
| 5 | 秋田 | Akita | AT | |||
| 6 | 山形 | Yamagata | YG | |||
| 7 | 福島 | Fukushima | FS | |||
| 8 | Kanto | 茨城 | Ibaraki | IK | ||
| 9 | 栃木 | Tochigi | TG | |||
| 10 | 群馬 | Gunma | GM | |||
| 11 | 埼玉 | Saitama | ST | |||
| 12 | 千葉 | Chiba | CB | |||
| 13 | 東京 | Tokyo | TO | |||
| 14 | 神奈川 | Kanagawa | KN | |||
| 15 | Chubu | 新潟 | Niiagta | NG | ||
| 16 | 富山 | Toyama | TY | Takaoka-shi | ||
| Toyama-shi | ||||||
| 17 | 石川 | Ishikawa | IS | |||
| 18 | 福井 | Fukui | FI | |||
| 19 | 山梨 | Yamanashi | YN | |||
| 20 | 長野 | Nagano | NN | |||
| 21 | 岐阜 | Gifu | GF | |||
| 22 | 静岡 | Shizuoka | SO | |||
| 23 | 愛知 | Aichi | AC | |||
| 24 | Kinki | 三重 | Mie | ME | ||
| 25 | 滋賀 | Shiga | SI | |||
| 26 | 京都 | Kyoto | KT | |||
| 27 | 大阪 | Oosaka | OS | |||
| 28 | 兵庫 | Hyogo | HG | |||
| 29 | 奈良 | Nara | NR | |||
| 30 | 和歌山 | Wakayama | WK | |||
| 31 | Chugoku | 鳥取 | Tottori | TT | ||
| 32 | 島根 | Shimane | SN | |||
| 33 | 岡山 | Okayama | OY | |||
| 34 | 広島 | Hiroshima | HS | |||
| 35 | 山口 | Yamaguchi | YC | |||
| 36 | Shikoku | 徳島 | Tokushima | TK | ||
| 37 | 香川 | Kagawa | KW | |||
| 38 | 愛媛 | Ehime | EH | |||
| 39 | 高知 | Kouchi | KC | |||
| 40 | Kyushu | 福岡 | Fukuoka | FO | Fukuoka-shi | FK |
| Kitakyusyu-shi | KT | |||||
| Nogata-shi | NG | |||||
| Kurume-shi | KR | |||||
| 41 | 佐賀 | Saga | SG | |||
| 42 | 長崎 | Nagasaki | NS | North | NH | |
| South | SH | |||||
| 43 | 熊本 | Kumamoto | KM | |||
| 44 | 大分 | Ooita | OI | |||
| 45 | 宮崎 | Miyazaki | MZ | |||
| 46 | 鹿児島 | Kagoshima | KS | |||
| 47 | 沖縄 | Okinawa | ON |
3.2.3 Prefecture ID
There are 47 prefectures in Japan, and we assigned an ID to each prefecture using an abbreviated form by referring to the BSL corpus project.
We have one-site-filming to Nara prefecture and Gunma prefecture in first stage of this project and several-site-filming to Nagasaki prefecture and Fukuoka prefecture in second stage of this project. The difference between one-site-filming and several-site-filming is whether we divide the prefecture into two or more. The case in which the prefecture has one Deaf school, we had one-site-filming. On the other hand, the case in which the prefecture has two or more Deaf schools, we divided into the regions aligning with each Deaf school area.
3.2.4 Participant ID
In the animation task, the narrator who had watched "Canary Row" sat
on the right (as we viewed the stage). The recipient who had not seen
it sat on the left (as we viewed the stage). We placed numbers on the
back of each chair to identify each participant for the purposes of
data analysis. We set the abbreviation for the prefecture as shown in
Table

Figure 4: Participant ID tag
(Participant IDs were temporally assigned in filming by camera clues. They were modified after filming (ex. G-01 to GM0150.)
3.2.5 File names
Video files, Word files and ELAN eaf files were named as per the
following example. In ***, we put the following task names: Ani
(animation task), Cur (Curry recipe task), Pro (Proud of your country
task), ReS (Regional Signing), Lex (lexical elicitation), and Int
(Interview).

Figure 5: File name
3.2.6 Tier names
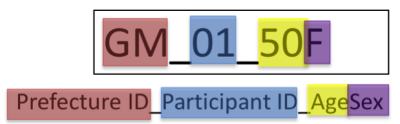
Figure 6: Tier name(one-site filming)
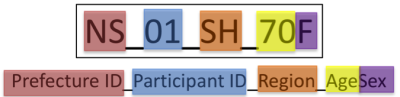
Figure 7: Tier name(seberal-site)
| Prefecture | File name | Tier | name | |
|---|---|---|---|---|
| Right | Left | |||
| Gunma | 1 | GM_01-02 | GM_01_50F | GM_02_50F |
| 2 | GM_03-04 | GM_03_70M | GM_04_70M | |
| 3 | GM_05-06 | GM_05_30M | GM_06_30M | |
| 4 | GM_07-08 | GM_07_30F | GM_08_30F | |
| 5 | GM_09-10 | GM_09_60F | GM_10_60F | |
| 6 | GM_11-12 | GM_11_70F | GM_12_70F | |
| 7 | GM_13-14 | GM_13_40F | GM_14_40F | |
| 8 | GM_15-16 | GM_15_40M | GM_16_40M | |
| 9 | GM_17-18 | GM_17_50M | GM_18_50M | |
| 10 | GM_19-20 | GM_19_60M | GM_20_60M |
| Prefecture | File name | Tier | name | |
|---|---|---|---|---|
| Right | Left | |||
| Nara | 1 | NR_01-02 | NR_01_70M | NR_02_70M |
| 2 | NR_03-04 | NR_03_50F | NR_04_50F | |
| 3 | NR_05-06 | NR_05_60M | NR_06_60M | |
| 4 | NR_07-08 | NR_07_70F | NR_08_70F | |
| 5 | NR_09-10 | NR_09_60M | NR_10_60M | |
| 6 | NR_11-12 | NR_11_40M | NR_12_40M | |
| 7 | NR_13-14 | NR_13_40F | NR_14_40F | |
| 8 | NR_15-16 | NR_15_30M | NR_16_30M | |
| 9 | NR_17-18 | NR_17_50M | NR_18_50M | |
| 10 | NR_19-20 | NR_19_40M | NR_20_40M |
| Prefecture | File name | Tier | name | |
|---|---|---|---|---|
| Right | Left | |||
| Nagasaki | 1 | NS_01-02 | NS_01_SH_70F | NS_02_SH_70F |
| 2 | NS_03-04 | NS_03_SH_30F | NS_04_SH_50F | |
| 3 | NS_05-06 | NS_05_NH_70F | NS_06_SH_70F | |
| 4 | NS_07-08 | NS_07_SH_50M | NS_08_NH_30M | |
| 5 | NS_09-10 | NS_09_SH_60M | NS_10_SH_70M | |
| 6 | NS_11-12 | NS_11_SH_40F | NS_12_SH_40F | |
| 7 | NS_13-14 | NS_13_NH_70M | NS_14_NH_70M | |
| 8 | NS_15-16 | NS_15_SH_40M | NS_16_SH_40M |
| Prefecture | File name | Tier | name | |
|---|---|---|---|---|
| Right | Left | |||
| Fukuoka | 1 | FO_01-02 | FO_01_KT_70F | FO_02_KT_60F |
| 2 | FO_03-04 | FO_03_NG_50F | FO_04_NG_40F | |
| 3 | FO_05-06 | FO_05_FK_80F | FO_06_FK_70F | |
| 4 | FO_07-08 | FO_07_FK_40F | FO_08_FK_50F | |
| 5 | FO_09-10 | FO_09_KR_50M | FO_10_KR_50M | |
| 6 | FO_11-12 | FO_11_KT_70M | FO_12_KT_70M | |
| 7 | FO_13-14 | FO_13_NG_70M | FO_14_NG_70M | |
| 8 | FO_15-16 | FO_15_KR_70M | FO_16_KR_70M |
| Prefecture | File name | Tier | name | |
|---|---|---|---|---|
| Right | Left | |||
| Ishikawa | 1 | IS_01-02 | IS_01_70M | IS_02_70M |
| 2 | IS_03-04 | IS_03_20M | IS_04_20M | |
| 3 | IS_05-06 | IS_05_50M | IS_06_50M | |
| 4 | IS_07-08 | IS_07_80M | IS_08_80M | |
| 5 | IS_09-10 | IS_09_60M | IS_10_60M | |
| 6 | IS_11-12 | IS_11_30M | IS_12_30M | |
| 7 | IS_13-14 | IS_13_40M | IS_14_40M |
4 Translation and Annotation Conventions
This chapter consists of four sections: 1) practical steps, 2) representation of time, 3) translation conventions, 4) annotation conventions.
4.1 Practical steps
Basically, we perform two steps when making annotations: 1) translation into text: sign language interpreters translate sign language into written Japanese. They create Gloss, Word-order-translations, and Idiomatic translations in Microsoft Word. They then ask native signers who live in different regions of Japan to check the translations using their native sense. 2) Referring to the text in Word created in step 1, native signers annotate the features of hand movements for each unit of Gloss and units of utterances in ELAN to observe the temporal relationships between or within them.
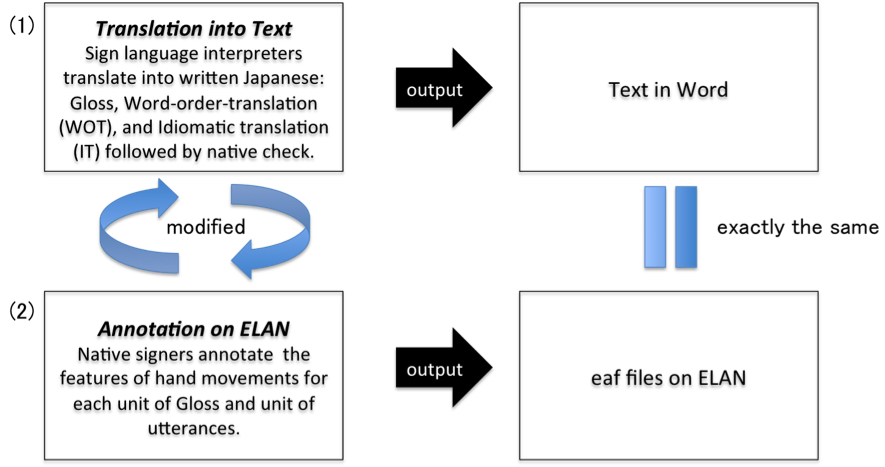
Figure 8: Practical steps in translation and annotation
After making the translation and annotations, we modify each file in a circulatory way using the findings noted in the working process of each, as shown in Fig.8. We pay close attention to making the information in these files exactly the same.
4.2 Representation of time

Figure 9: Schematic of translation in Microsoft Word
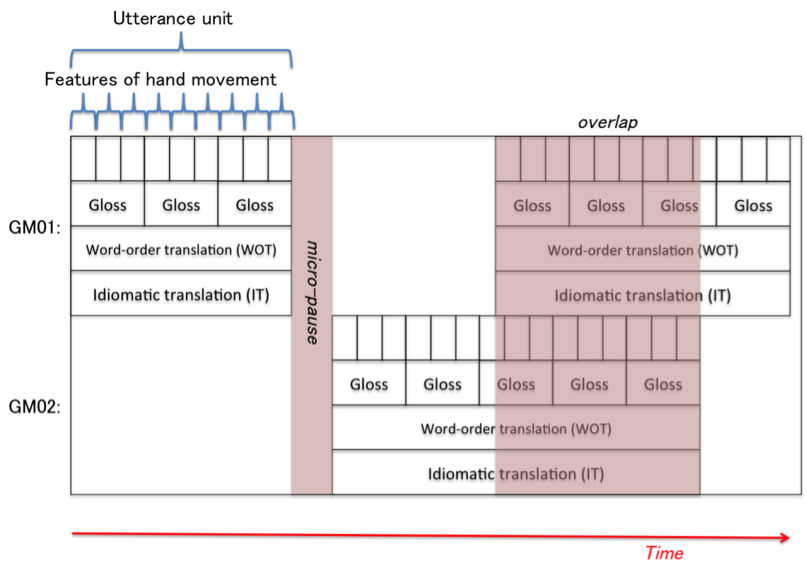
Figure 10: Schematic image of annotation in ELAN
When translated into Word (Fig. 9), each line has an independent time axis. If line 01 and line 02 were to overlap, it would be difficult to represent their temporal relationships. Conversely, because annotations in ELAN (Fig. 10) have one time axis, it is easy to represent a micro-pause or show that two lines are overlapped. However, the annotation scheme of ELAN, due to the need to scroll to see the next and following lines, can make it difficult to find a sequential relationship, e.g. question and answer in speech act theory, conversation analysis (CA), and the discourse structure of narratives. We are trying to not only collect data but also build a hybrid notation system like a 'transcript' in CA (Jefferson, 1986) in this project.
4.3 Translation Conventions
4.3.1 Gloss
Translation at the Gloss level is a common method of learning sign language for beginners and training in interpretation skills at an advanced level.
EXAMPLE (Gloss-ENG) NOW/PT/COMIC1(M:ma-n-ga)/THEATER-PLAY (M:a-ni-me)/PT/= =FS: A(M:a)NI(M:ni)ME(M:me)/SIGN-LANGUAGE/WHAT/PT:G02/
We explain how each symbol in the translation conventions is aligned, using the example above.
NOW : Gloss (word), which is usually in a lexical databases
/ : a Gloss boundary
PT : Pointing by hands. Here, we do not specify which hand points. When the direction and reference of pointing are ambiguous, we do not label anything after PT.
COMIC1 : When there are several representations of this meaning, we add a number to distinguish one from others.
THEATER-PLAY : In a case where signing consists of one movement or one Gloss, however, in spoken language, we need two words to represent the same meaning.
M:a-ni-me : Mouthing of a-ni-me (abbreviation of 'animation') represented in Mora rhythms, it is three Mora combinations, a+ni+me. ‘COMIC1 (M:ma-n-ga)’ means the signer moves her/his lips ma-n-ga while signing COMIC1. In cases where there are no parentheses around M: a-ni-me, this means the mouth movement has a syntagmatic relation with other Glosses.
= : Sign production continues across line break.
FS: A-NI-ME: Finger-spelling of A-NI-ME, represented in Mora rhythms as the same as mouthing.
PT:G02 : Signer points at interlocutor in front of her or him by hand. Usually this is PT2 in previous studies of the grammatical aspect of signing. We try to avoid putting the function of indexicality in the translation level.
HS:KI : The signer uses a specific hand shape when producing a sign. There are cases where two phonetically distinct signs are represented with the same gloss and this description is used order to specify which sign is being employed.
Here we explain other symbols, which have already been set in working process
MG : pa: Mouth gesture that has grammatical function (e.g., tense, pronoun etc.)
CLIMBING-UP (CL: drainpipe): The Gloss includes representation of classifier (CL). In this case, the CL representation is classified by the verb type, climbing up, with inside drainpipe.
CL : Although it is impossible for the annotators to analyze what kind of CL it is, there is some king of CL here.
? : impossible to read.
?: CAT : Although it is impossible for the annotators to read clearly, they have some candidates in mind (in this case “cat”).
D : Although it is impossible to read, there is a part of signing (nearly equal disfluency).
D: CAT : Although it is impossible to read, there is some signing (nearly equal disfluency). The annotators have some candidates (in this case “cat”).
PT : object name: Pointing to a concrete object.
PT: CL : Pointing to CL, which is signing with the other hand
PT: CL-lost : Pointing to the space where CL was previously represented
PT: RU : Pointing in an upper right direction (from the signer’s perspective)
PT: RU (PET BOTTLE) :Pointing in an upper right direction with the meaning of PET bottle in context
PT: RU (people’s name) : Pointing in an upper right direction with the meaning of 3rd person
4.3.2 Word-order translation (WOT)
The word-order translation (WOT) tier serves to maintain the original word order; at this level, the text in translation is very consciously written in a grammatically inaccurate manner. This kind of translation always conveys a strong impression to the audience, illustrating how much signed language differs from spoken language.
EXAMPLE (WOT-ENG) Now, comic, theater play, animation... Animation, how do you sign?
4.3.3 Idiomatic translation (IT)
The idiomatic translation (IT) tier serves as ideal forms of sentences as language, in this case English.
EXAMPLE (IT-ENG) I just watched a cartoon, uhm, how do you sign "cartoon"?
4.3.4 Multilingual environment, line numbers and participant ID
English and Japanese translations were prepared for establishing a multilingual environment of language research and communication studies in sign languages. All lines in both languages coincide with each other.
EXAMPLE: 01> GM01: (Gloss-JPN) 今/PT/まんが1 (M:ma-n-ga)/劇 (M:a-ni-me)/PT/= =FS:A-(M:a)NI-(M:ni)ME-(M:me)/手話/何/PT:G02/ (Gloss-ENG) NOW/PT/COMIC1(M:ma-n-ga)/THEATER-PLAY (M:a-ni-me)/PT/= =FS: A(M:a)NI(M:ni)ME(M:me)/SIGN-LANGUAGE/WHAT/PT:G02/ (WOT-JPN) 今 まんが アニメを…アニメって手話は何 あなたは? (WOT-ENG) Now, comic, theater play, animation... Animation, how do you sign? (IT-JPN) 今、アニメを見たんだけど、ねえ、アニメって手話はどうやる? (IT-ENG) I just watched a cartoon, uhm, how do you sign "cartoon"? 02> GM02: (Gloss-JPN) まんが1(M:a-ni-me)/まんが2(M:cont.)/まんが1(M:a-ni-me)/= =まんが1(M:cont.) (Gloss-ENG) COMIC1(M:a-ni-me)/COMIC2 (M:cont.)/COMIC1 (M:a-ni-me)/= =COMIC1(M:cont.)/ (WOT-JPN) まんが まんが まんが (WOT-ENG) Comic, comic, comic (IT-JPN) うーん、こうかな? (IT-ENG) Uhm, like this (I guess)? 03> GM01: (Gloss-JPN) まんが1+まんが2 (M:a-ni-me)/(.)/まんが2/まんが1(M:a-ni-me)/= =PT/見た/PT/見た/PT/ (Gloss-ENG) COMIC1+COMIC2(M:a-ni-me) /(.)/COMIC2/COMIC1 (M:a-ni-me)/= =PT/WATCHED/PT /WATCHED/PT/ (WOT-JPN) まんが まんが まんが まんが…まんがを見た 見た。 (WOT-ENG) Comic, comic, comic, comic…, (I) watched a comic, watched. (IT-JPN) こうか…、で、アニメを見たの。 (IT-ENG) Okay, like this. So, I just watched a cartoon.
4.4 Annotation conventions
Applying gesture phases to signing movements
One of our original points was to establish a physical and hand movement unit smaller than Gloss, called a Movement Unit. We applied the concept of the gesture unit (GU) proposed by Kendon (1972, 1980, 2004) to annotate the beginning and end points of signed turns. The GU is the interval between successive rests of the limbs, rest positions, or home positions. A GU consists of one or several gesture phrases. A gesture phrase is what we intuitively call a “gesture,” and it, in turn, consists of up to five phases: preparation (optional), stroke (obligatory in the sense that a gesture is not said to occur in the absence of a stroke), retraction (optional), and pre- and post-stroke hold phases (optional). When analyzing overlapping communications in conversations, it is important to note the timing of the expressions of both the signer and recipient. In signed conversations, articulation involves hand signs that appear in front of the participants; this process of articulation is comparable to the visible lip movements made by those involved in spoken conversations. Using this methodology, we can observe how participants engage in an articulation phase in which signers move their hands to the signing space from the home position as a signal for the start of turn-taking in interactions.
4.4.1 Setting tiers in ELAN
We prepared 17 tiers per participant in ELAN. In the case of a dialogue task, we have 34 tiers in total (Fig. 11).
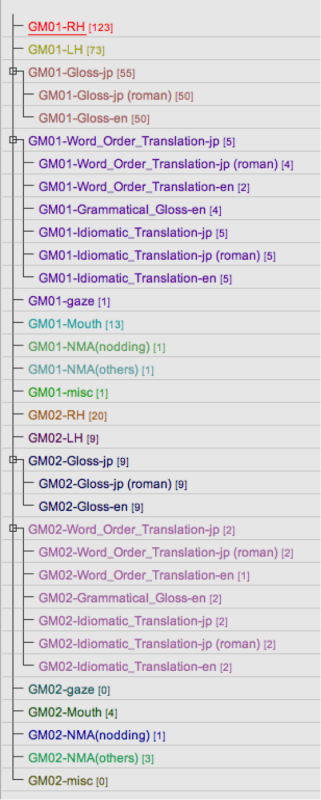
Figure 11: Tiers in ELAN
4.4.2 Movement tiers
Hand signing is divided into left and right hand per signer (e.g. RH and LH). These tiers have several labels for annotating each movement in signing, including preparation (prep), pre-stroke hold (pre-s-h), stroke (str), post-stroke hold (post-s-h), retraction (ret), and more. We consider the preparatory and stroking movement meaningful figures that constitute a signed token.
prep : Preparation phase of signing. Signers raise their hands from the home or rest position to the signing space.
pre-s-h : Pre-stroke hold. The phase in which the hand shape and the hand position are sustained before the next stroke phase.
str : Stroke. The phase in which the core part of a sign is presented, with the hand changing shape and moving within the signing space.
post-s-h : Post-stroke hold. The phase in which the hand shape and the hand position are sustained after the previous stroke phase.
ret : Retraction. The phase in which the hands are returned to the home position or rest.
hold : An independent holding phase.
4.4.3 Gloss tiers
The Gloss, called Word_for_Word in ELAN (Fig. 12), basically consists
of at least one pair of prep and stroke. This is a signed token
including non-lexical element, e.g. disfluency, truncated. The reason
there isn't a well-structured lexical database for JSL is that we
don’t prepare the linkage of a lexical database like the BSL corpus
(Johnston 2008).
We assign one tier of Gloss per signer, that is, we don’t separate each hand like the BSL corpus. If a case where each hand has a different meaning at the same time, we note as: ‘R:/PT+L:/3,’ which means right hand represents PT (pointing) and left hand represents number 3.
EXAMPLE
\begin{eqnarray*} L:/3 + R:/ PT:L-3 \end{eqnarray*}

Figure 12: List buoy
The start point of Gloss is coincident with the beginning of prep of the dominant or meaningful hand at that time, and the end point of Gloss is coincident with the ending of str.
We use three written systems: Japanese in hiragana and kanji, Romanized Japanese, and English. We assign the role of parent to Japanese in hiragana and kanji, the other two systems are assigned the role of child to change the range of Gloss in one action in ELAN.
4.4.4 Utterance tiers
Applying the turn constructional unit to signed interactions
One purpose of this study was to apply the concepts of CA (e.g., turn-taking systems (Sacks et al., 1974), repair sequences (Schegloff et al., 1977), etc.) to signed dialogues and signed conversations. CA is the study of naturally occurring speech in social interactions. Sacks, Schegloff, and Jefferson (1974; SSJ) proposed several concepts related to turn-taking systems to analyze spoken conversational data.
We argue that these theoretical and methodological frameworks can be applied to the analysis of signed conversations. SSJ proposed the concept of a turn construction unit (TCU), which is a fundamental unit that differs from a sentence. SSJ assumed that the participants in a conversation are able to anticipate whether the ongoing TCU will be closed by the current speaker. One TCU sometimes has several possible completion points; phrasal boundaries, intonation units, and so on at the end of some TCUs, considered transition-relevance places (TRPs).
An utterance consists of one or several Glosses. The annotators who are native signers who segment using their native sense. This is close to utterance and GU as mentioned above. TUC is represented by seven tiers, including three notations: WordOrderTranslation, Grammatical Gloss and IdiomaticTranslation on ELAN (Figure 3). Translations have multilingual environments as well as Gloss.
4.4.5 NMA tiers
We prepared four tiers for non-manual actions: gaze, mouth, NMA (nodding), NMA (others). These modalities sometimes are used at the same time, meaning they are not in an exclusive relationships.