Hadoop関連イベントで講演を頼まれたときに2時間弱で作ったMapreduceシステムです。講演直前に作った簡易実装ですが、Mapreduceの動作がよくわかるように実装してあります。なお、Hadoopなどは既存システムは使わずにスクラッチから作ってあります。
実行手順
1. samplesというディレクトリにあるMapperエージェント(Mapper.jar)をロードしてください
2. samplesというディレクトリにあるReducerエージェント(Mapper.jar)をロードしてください
次ようなエージェントが実行されているはずです。
ここでMapper AgentのExecutorで指定するのが、Mapper対象の処理を定義するエージェントです。ここではHadoopの定番例題がWord Countであることを意識して、同様のWord Count処理をしてくれるエージェントです。このエージェント自体は移動先のファイルを読み込んで、Word Count処理をするだけです。もうひとつReducer AgentはReduce処理をするエージェントです。
さて、Mapper AgentのTarget URLに移動先のコンピュータ、Target Fileに処理をしたいファイル名を入力します。そしてMapボタンを押すと、上記の二つのエージェントに加えて、次の二つのエージェントが生成されて、画面は次のようになります(ウィンドウの位置を変えてあります)。
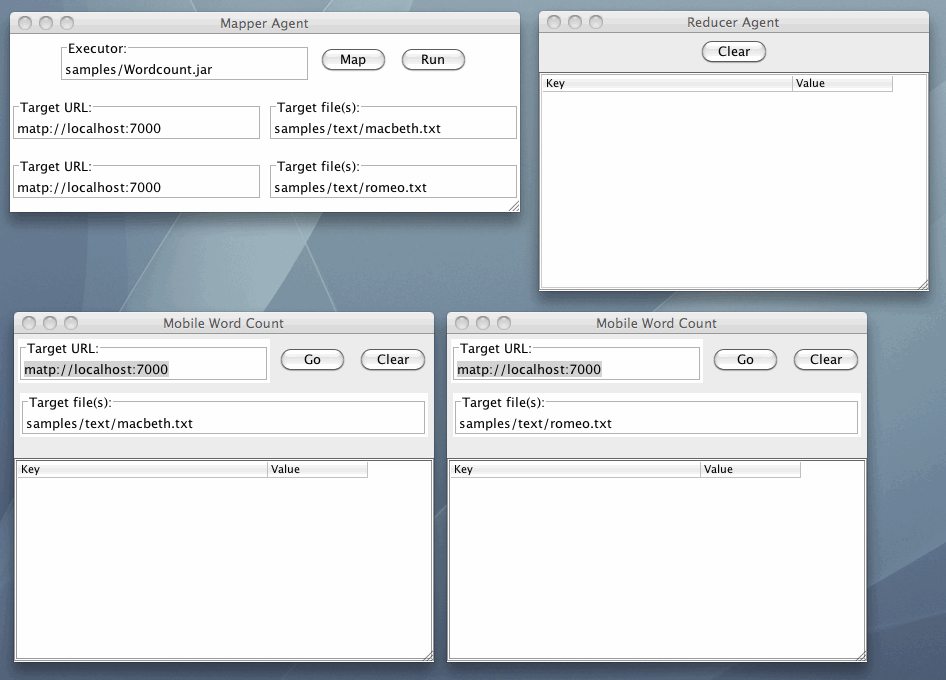
ここで左下のエージェントはシェークスピアのマクベスのテキストを調べ、右下はロミオとジュリエットのテキストを調べます。このMapボタンを押すと、処理をするエージェントが二つ起動します。そしてMapperエージェントのRunボタンを押すと、この二つのエージェントが、Mapperエージェントで指定したコンピュータに移動して、そのコンピュータにあるファイルを読み込んで、Word Count (単語数)を数えます。そして処理が終わると、元のコンピュータにもどってきて、Reducerエージェントに結果を通知します。その結果が画面は例えば次ぎようになります。
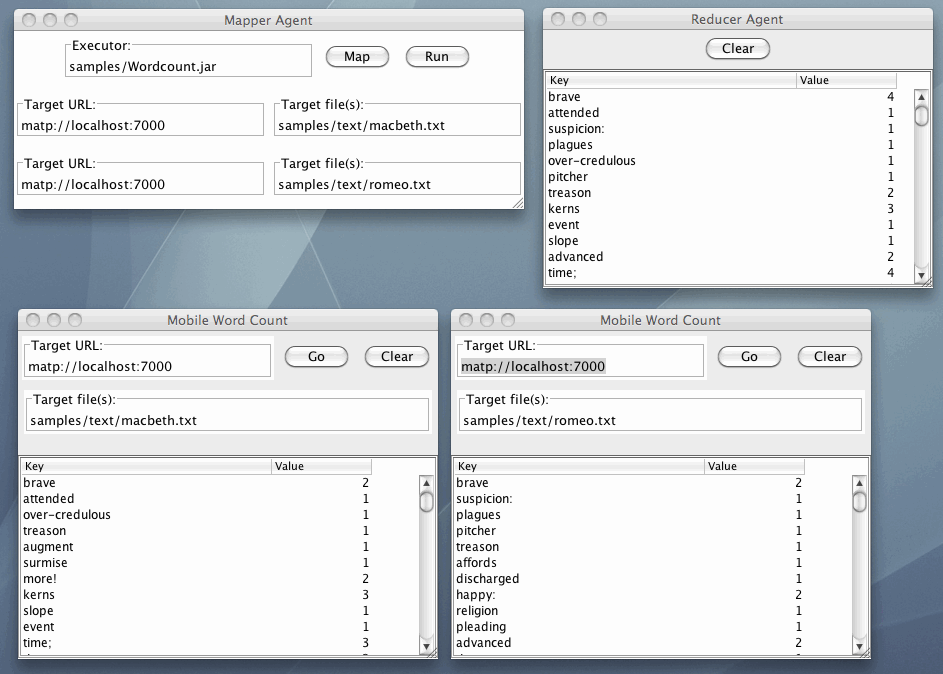
二つのWord Countエージェントの処理結果は各エージェントに内蔵したKey-Value store形式のデータベースがはいっています。それをReducerエージェントのKey-Value store形式のエージェントに渡します。このときWord Countは出現単語数を数える処理ですから、Reducerエージェントは二つのエージェントから同じ単語があればその合計を登録します。この状態ではKey-Value storeはソートされていないので、各エージェントのValueと書かれた部分をクリックすると、降順または昇順にソートされます。例えば単語Theの数に注目してみましょう。
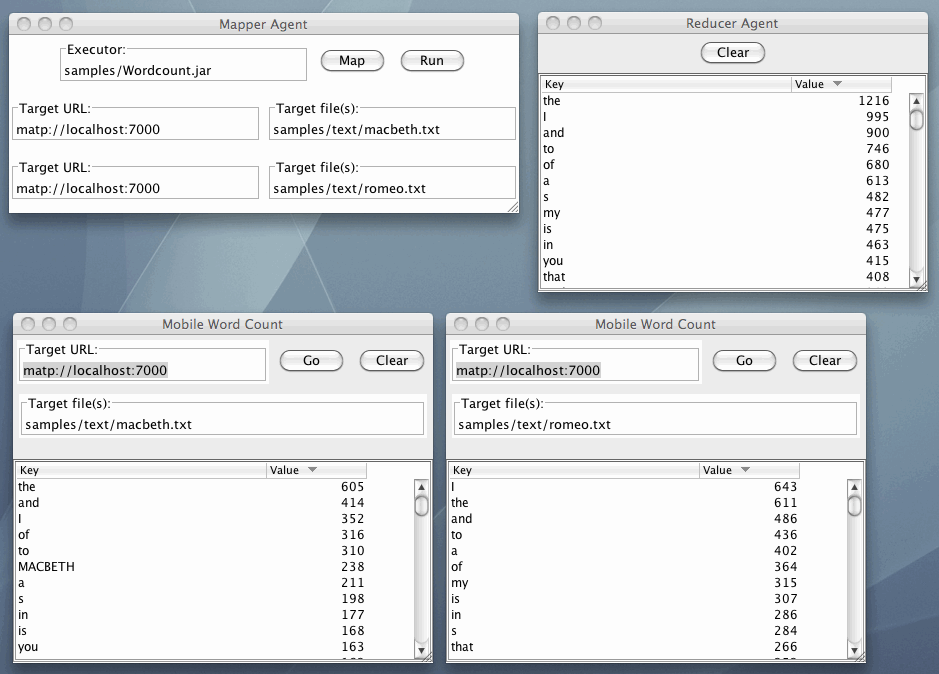
二つのWord Countエージェントでは、Theの出現回数はそれぞれ、605回と611回。そしてReducerエージェントでは1216ですから、加算されていることがわかります。なお、Wordcount.jarは単体でも動かすことができます。
Word Countの例題に関してはモバイルエージェントでやる必要があるかという疑問ですが、逆に処理結果が小さくなる場合はHadoopなどよりも有利にあるでしょう。なお、この例題は講演用デモなので多くの部分を手を抜いていますが、ある程度汎用性を持たせるように改造されれば、卒論や修論に十分になると思います。ただし、時間がある状況でもないので、問い合わせいただいてもお返事でないかもしれません。
〒101-8430 東京都 千代田区 一ツ橋 2-1-2
国立情報学研究所 アーキテクチャ科学研究系
佐藤一郎 (E-mail: ichiro [at] nii.ac.jp)
Tel: 03-4212-2546
http://research.nii.ac.jp/~ichiro/