
World Wide Web(WWW)の登場により、何百万の人がインターネットを利用する ようになっています。Microsoft Internet Explorer や Netscape Navigator などに代表されるWebブラウザを使えば、マウスでクリックするだけで世界中 のホームページにアクセスできるようになります。本章では、その背後で動い ているWeb技術について概説し、そのWebクライアントやサーバの作成方法を示 します。
ところで、Webブラウザが遠く離れたホームページサイトからどのようにホーム ページをダウンロードしてくるののでしょうか。それを実現しているのが 「Hyper Text Transfer Protocol(HTTP)」とよばれる通信プロトコルであり、 電子メール送受信で利用するSMTPやPOP3と同様にTCP通信上に実現されています。
「HTTP」は他のTCP/IP通信と同様に、通信接続を待つ側であるサーバと、通信 接続を要求する側であるクライアントに別れています。Netscape Navigatorや Microsoft Internet ExplorerなどのWebブラウザはHTTPのクライアント側プロ グラムです。一方、サーバ側は、HTTPサーバやWebサーバ、ホームページサー バなどと呼ばれ、ホームページの参照先で動作しているものです。
HTTPサーバは、HTTPクライアントであるWebブラウザから「○○○.htmlといファ イルを送れ」という要求があると、○○○.htmlファイルを読み込んでその中 身を送り返すということ永遠に繰り返しているプログラムです。例えば、 「http://www.some.where.co.jp/index.html」とは「www.some.where.co.jp」 というIPアドレスをもつコンピュータ上で動作するHTTPサーバに、 「index.html」というファイルを読み込んで、その中身を送り返せということ になります。HTTPサーバとWebブラウザの関係を大まかにみていきましょう。
ここで(1)と(2)、(5)、(7)はTCP/IPによる通信接続及び切断と同 様です。詳細はTCP/IPの解説を参照して下さい。また、(6)はHTMLファイル やGIFファイルなどをどのように表示するのかという問題です。これはWWWブラ ウザプログラムに任せられています。WWW特有となるのは(3)と(4)です。 (3)はWebブラウザからHTTPサーバにファイルの転送して欲しいというお願い メッセージを送ること、(4)はHTTPサーバがそのお願いに従ってファイルの 中身をHTTPサーバに送り返すことに相当します。
ここで問題となるのが、「WebブラウザからHTTPサーバへの要求」と「WWWサー バからHTTPサーバへの返答」の仕方です。もしかすると、Webブラウザが Netscape社のNavigator、HTTPサーバがMicrosoft社の Internet Information Server (IIS)となっているかもしれません。違う会社で作られたWebブラウザ とHTTPサーバがそれぞれの流儀で要求や返答を行うと、ホームページアクセス はできなくなってしまいます。
そこで、WebブラウザとHTTPサーバの間のやり取りの仕方には、 HTTP (HyperText Transfer Protocol)と呼ばれる約束事があり、そこで要求や返答 の仕方が厳密に決められています。そして、このHTTPの約束事に従っている限 りは、A社製のWebブラウザからB社製のHTTPサーバのホームページをアクセス ができるようになります。
コラム:ハイパーテキスト
HTTP(HyperText Transfer Protocol)の「HyperText」(ハイパーテキスト)と はいったいどんな文書なのでしょうか。通常の文書は連続してアクセスされる のに対し、ハイパーテキストでは、ある文書中の節やキーワードなどの特定部 分から別の文書にリンクという概念により繋げられています。そして、このリ ンクを自由に辿ることにより、文書中のキーワードからそのキーワードに関連 した別の文書を見つけ、アクセスすることができるようになる。ホームページ のHTMLファイルはハイパーテキストの一種です。なお、ハイパーテキストをそ のリンクを辿りながら別のハイパーテキストを見つけていく過程を航行 (navigation)といいます。 Netscape社のWebブラウザのNetscape Navigaterの 名称はこれに由来します。
コラム:Hyper Text Markup Language (HTML)
コラム:eXtensible Markup Language (XML)
WebブラウザとHTTPサーバはHTTPに定められた手順で通信をします。 HTTPはWWWのために設計された通信プロトコルで、その通信手順は WebブラウザからHTTPサーバに送られる要求であるHTTPリクエストと、 HTTPサーバからWebブラウザに送られる返答であるHTTPレスポンスの 組となっています。HTTPの約束事ではこのHTTPリクエストと HTTPレスポンスの仕方を決めたものであり、逆に、通信ネットワーク がどのように接続されているかや、データが実際にはどのように ネットワーク中を転送されるかなどはHTTPでは定義していません。 これらは、HTTPより下位の通信プロトコルであるTCP/IPなどによって 決められます。このことは逆に、HTTPは通信ネットワークの具体的な 実現方法によらず、実現可能な通信方法となり、さまざまな 通信ネットワークで利用されることになります。
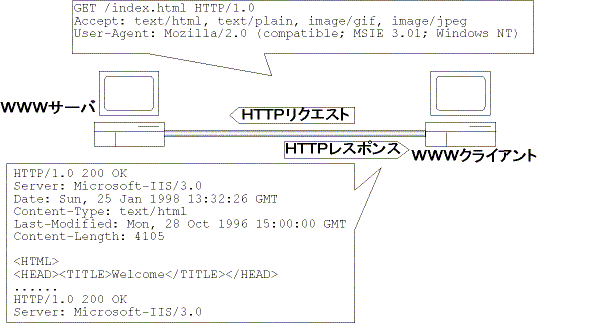
HTTPリクエストはWebブラウザからホームページサーバに送られる要求 (例えばホームページ内容の送信要求)です。その中身は、 リクエスト行と付加情報に分かれています。
リクエスト行は次のように与えられます。
|
|
「メソッド」、「URI」、「HTTPバージョン番号」の間は スペースで区切られ、それぞれは次のような意味を持ちます。
|
メソッド |
WebブラウザからHTTPサーバの要求の種類。 GETやPOSTなど予め決められている |
|
URI(Universal Resource Identifier) |
|
|
HTTPバージョン |
HTTPのバージョンが1.0ならばHTTP/1.0、1.1ならばHTTP/1.1となる |
HTTPバージョン1.0のメソッドには次のものがあります。
|
メソッド名 |
メソッドの意味 |
|
GET |
オブジェクト(情報)をWebブラウザに返す |
|
POST |
HTTPサーバにオブジェクト(情報)を送る |
|
HEAD |
オブジェクトの情報(作成日付、サイズ)をWebブラウザに返す |
|
PUT |
HTTPサーバにオブジェクト(情報)を送り、HTTPサーバ上で保存 |
|
DELETE |
HTTPサーバのオブジェクト(情報)を削除 |
ただし、多くのHTTPサーバは「GET」と「POST」しか対応していません。このた め、それ以外のメソッドのリクエストを送っても処理をされることはありませ ん。なお、「POST」はCGI(Common Gateway Interface)と呼ばれるスクリプト プログラムで使われます。CGIはHTTPサーバで実行され、POSTを用いたHTTPリク エストがあると、そのHTTPサーバは対応したスクリプトプログラムを実行して、 その結果をあたかもホームページのようにしてWebブラウザに返すというもの です。ホームページによく見かけるアクセスカウンタなどもCGIを利用するこ とが多いです。
リクエストを補足する情報。付加情報には、このHTTPリクエストを送ったWWW ブラウザが受け取れるデータの種類やWebブラウザの種類などがあります。ま た、有料ホームページを利用する際の身元確認や支払い許可に関する情報も付 加情報として送られます。付加情報が複数個あるときは、一行一行分けて書か れ、各行には付加情報の名前、そしてその情報を書いていきます。
付加情報はHTTPリクエストのオプションであり必須ではありません。このため、 HTTPサーバがすべての付加情報に対応しているわけではありませんし、逆に、 WebブラウザによってはHTTPに定められていない付加情報をつけて送るものが あります。HTTPサーバはこのように対応できない付加情報を受け取ったときは 無視していまいます。代表的な付加情報をあげましょう。
|
付加情報の名前 |
付加情報の意味 |
|
Accept: |
リクエストを送ってきたWebブラウザが受理できるデータ形式 (MIMEタイプ)。例、text/html、image/gif, image/jpeg, image/gif, image/x-jg, */*などがある。 「*/*」はどんなデータ形式も受け取れることを示すワイルドカード。 |
|
If-Modified-Since: |
指定日付より新しいオブジェクトだけを返すように指示。 更新されていないデータの送信が省ける。 |
|
Accept-Language: |
Webブラウザが受理できる言語、日本語ならja、 英語ならenと書く。 |
|
User-Agent: |
このHTTPリクエストをしたWebブラウザの種類 |
|
UA-pixels、UA-color、UA-CPU、UA-OS:など |
このリクエストをしたWebブラウザの実行環境、 画面の解像度、色数、CPUやOSの種類など |
以下はWebブラウザ(Microsoft Internet Explorer 3.01)から 「http://133.65.200.181/index.html」というホームページを みようとしたときに、Webブラウザが送ったリクエストです。
GET /index.html HTTP/1.0 Accept: image/gif, image/x-xbitmap, image/jpeg, image/pjpeg, image/x-jg, */* Referer: http://133.65.200.181/index.html Accept-Language: ja, en UA-pixels: 1280x1024 UA-color: color16 UA-OS: Windows NT UA-CPU: x86 User-Agent: Mozilla/2.0 (compatible; MSIE 3.01; Windows NT) Host: 133.65.200.181 Connection: Keep-Alive
ここで重要なのは先頭の「GET /homepage/index.html HTTP/1.0」の部分です。 「GET」は「オブジェクト(つまり情報)を送れ」という要求であることを示 し、次の「 /homepage/index.html」は送られるオブジェクトの名前 を示します。このオブジェクトの書き方をURI(Universal Resource Locator) と呼びます。URLのサブセットと考えればよいでしょう。この例で、予め決め られたディレクトリにある/homepage/index.htmlというファイルがそのオブジェ クトになります。最後の「HTTP/1.0」はHTTPのバージョンです。バージョンを わざわざいれるのは将来 HTTP が拡張され、その処理内容が変更されたとして も、「1.0」と書いてあればHTTPの1.0バージョンに適した処理をしてもらえる ようにするものです。
2行目以降の行は、このHTTPリクエストに対する付加情報で、省略するこ とが できます。「User-agent: …」はWebブラウザの種類です。そして、 「Accept:…」は、Webブラウザが受け取ることのできるデータ形式が、GIF形 式の画像データ、ビットマップ形式の画像データ、JPEG形式の画像データ… であり、最後の「*/*」よりどんなデータ形式でも受け取るということを示し ています。例えば、「image/gif」は画像データで、データ表現形式はGIF形 式のデータを受け取ることを示します。このように「データの種類/データの 表現形式」という形で、データ形式を定義する方法をMIMEタイプ形式といい ます。
なお、行の折り返しは、CR(ASCIIコードにおいて十進数で13の文字)、 LF(ASCIIコードにおいて十進数で10の文字)を連続して入れる約束になっ ています。
Netscape Navigator 3.02 (MacOS)からのHTTPリクエスト
GET /index.html HTTP/1.0 Connection: Keep-Alive User-Agent: Mozilla/3.02 (Macintosh; I; PPC) Host: 133.65.200.181 Accept: image/gif, image/x-xbitmap, image/jpeg, image/pjpeg, */*
どのWebブラウザが送ったHTTPリクエストも一行目のリクエスト行は 同じ形式となります。
MIMEタイプとは
Multipurpose Internet Mail Extensions の略。文書とは限らない様々な種類 のデータを交換するための表記ルール。文書以外の画像、音声、プログラムな どを含む電子メールを送り、相手がその画像、音声、プログラムを正しく表示 (発声?)できるようにするために提案された。HTTPと同様にRFCにより定義 されています。
MIMEタイプ
意味
text/plain
通常のテキストデータ(ASCIIテキスト)
text/html
HTML形式のテキストデータ
image/gif
GIF形式の画像データ
image/jpeg
JPEG形式の画像データ
audio/basic
サウンドデータ
video/mpeg
MPEG形式のビデオ画像データ
HTTPリクエストはWebブラウザからホームページサーバに送られる要求(例え ばホームページ内容の送信要求)です。その中身は以下の通り:
リクエストの成功や失敗などを示す番号を返す。例えば、 200はリクエスト成 功、404はリクエストした情報がない(ホームページのファイルがないなど)、 403はリクエストした情報は保護されていてアクセスできないなどがある。
|
|
「ステータスコード」はリクエストの結果を表す番号、 また、「理由」ではステータスコードの意味を簡単な文で示す。代表的なステータスコードは以下の通り
|
ステータスコード |
理由 |
意味 |
|
200 |
Document Follows |
リクエスト成功 |
|
304 |
Not Modified |
IF-Modified-Sinceの指定日付以降にオブジェクト(情報)が更新されていない |
|
401 |
Unauthorized |
特定者以外にはオブジェクト(情報)が保護されている |
|
402 |
Payment Required |
オブジェクト(情報)には料金を払いが必要 |
|
403 |
Forbidden |
リクエストしたオブジェクト(情報)は保護されていてアクセス不可能 |
|
404 |
Not Found |
リクエストしたオブジェクト(情報)がない(ファイルがない) |
|
500 |
Server Error |
リクエストされたメソッドが実装されていない |
レスポンス内の情報に関する付加情報。 リクエストされた情報のデータ形式や大きさ、ホームページサーバの種類など
転送をリクエストされたオブジェクト(情報)そのもの
例:ここでは先のリクエスト例に対応したレスポンスの例をあげます。
HTTP/1.0 200 Document follows Server: Microsoft Internet Server/4.0 Date: Mon, 9, Dec, 1997 19:17:05 GMT Content-type: text/html Content-length: 1234
<HTML> <HEAD><TITLE>Welcome to My Homepage</TITLE></HEAD> <BODY> <H1>Welcome to My Homepage</H1> <P> Underconstruction </P> </BODY> </HTML>
一行目の「HTTP/1.0」はHTTPのバージョンです。「200」はサーバへのリクエ ストが成功したことを示します。この後に、ホームページサーバの種類、送ら れてくる情報の種類や大きさなどが続きます。そして、 空行の後に情報その ものが入ります。上の場合は/homepage/index.htmlというファイルの中身が送 られることになります。
なお、リクエストされたホームページサーバは、そのリクエストされた情報の 種類や大きさの付加情報に加えることがあります。また、リクエストされた情 報はそのまま変更を加えることなくをWebブラウザにレスポンスとして送り返 します。
「Server: …」はHTTPサーバの種類、ここでは Microsoft社の Internet Server 4.0 であることを示しています。「Date:…」はレスポンスの日付。 「Content-type: text/html」は送り返されるオブジェクト(情報)が テキストデータで、HTML形式でデーが表現されていることを示す。 「Content-length: 1234」は送り返されるオブジェクト(情報)の バイトサイズです。
これらの付加情報はオプションであり必須ではなりません。 これらの情報を活かすかどうかはWebブラウザの処理に依存します。
HTTPリクエストやレスポンスはWebブラウザやHTTPサーバが代行 してくれます。しかし、遠隔端末を実現するコマンドである 「telnet」プログラムを利用すると、HTTPリクエストを手入力し、 その結果を見ることができます。
telnet を使うには、[アクセサリ] フォルダの [telnet] アイコンをダブルク リックするか、またはコマンドプロンプトで telnet と入力します。
telnet は、標準 telnet 通信ポート以外の通信ポートにも接続できます。 これは、telnet デーモン以外の何かに アクセスするために telnet クライアントが使われている場合に、 役に立ちます。リモート システムに接続すると、[Telnet] ウィンドウのタイト ル バーにリモート システムのシステム名が表示されます。
telnet でHTTPサーバに接続するには

画面にHTTPレスポンスが表示されるはずです。
用語説明:Webブラウザ
1993、94年頃、CERNというヨーロッパにある核物理の研究組織によって、 研究 論文の共有のため開発されました。ここはHTTPを開発したところでもあ ります。その後、1994年にアメリカのコンピュータ研究機関であるNCSAによっ て、 MosaicというWebブラウザ(無料)が開発されました。Mosaicは文書だけ でなく画像データも表示できたので、研究者以外にも利用されるようになり、 これ とともにWWWが広まりました。この頃はWWW、ホームページアクセ スのことを「モザイクする」と呼んでいました。1995年に入ると、Mosaicの開 発者が Netscape社を設立し、「Netscape Navigator」というWebブラウザ(商 品、有料)を開発しました。「Netscape Navigator」はNetscape社から簡単 にダウンロード・インストールができたために瞬く間に、世界中を席巻しまし た。しか し、その後、Bill Gates率いるMicrosoft社は「Netscape Navigator」 に対抗 すべく、OSメーカであるという立場を利用しながら 「InternetExplorer」と いうWebブラウザ(商品、しかし無料)を開発し、同 社のOSとの親和性を強調しながらマーケットシェアを広げつつあります。こ のため、1998年はじめ、 Netscape社は起死回生を狙い「Netscape Navigator」 を無料化、ソースプロ グラムの公開という大胆な策にでようとしています (1998年1月末現在)。
用語説明:HTTPサーバ(ホームページサーバ)
商用のものとしては、Netscape社の「Communication Server」やMicrosoft 社 の「Internet Information Server」が代表的です。非商用のものには 「CERN httpd」、「NCSA httpd」、「apachie」などがあります。
ホームページアクセスをしたとき、Webブラウザと HTTPサーバがHTTPに従っ てどのようなやり取りをするのかを、 順を追って説明していきます。ここで はHTTPサーバのIPアドレスを「some.where.ac.jp」とします。
インターネットのどこからか接続要求があるのを待ちます。 HTTPでは通信 ポートの80番を用いますので、 このポート番号を通したTCP通信接続を待機 しています。
ここではユーザから「http://some.where.ac.jp/homepage/index.htmlとい う URLを開く」という要求があったとしましょう。このURLは、ユーザ が手入力されたのかもしれませんし、ユーザが現在参照しているHTMLから このURLにリンクが張られていて、そのリンクを参照しようとしたのかもし れません。

通信接続を待っています。接続要求があると接続し、 HTTPリクエストが送 られてくるのを待ちます。
URLからHTTPサーバコンピュータのIPアドレス(some.where.ac.jp)を特定し、 そのコンピュータの80番の通信ポートに対してTCP接続要求を送ります。

接続したWebブラウザから送られて来るHTTPリクエストを受け取ります。
URLからHTTPリクエストを作ります。この場合、 オブジェクト(情報) の返信要求ですからメソッドは「GET」、 オブジェクトのURIは /homepage/index.htmlとなります。この他、付加情報を加えた以下のような HTTPリクエストをHTTPサーバに送信します。
GET /homepage/index.html HTTP/1.0 User-agent: Microsoft Explorer for Windows/3.0 Accept: text/plain Accept: text/html Accept: image/gif Accept: image/jpeg
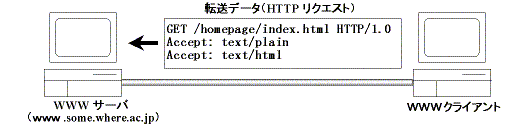
HTTPリクエストの内容を解析します。このHTTPリクエストでは先頭行に 「GET」 があるので、オブジェクト(情報)の返信要求であることがわかりま す。そして、そのオブジェクトの名前が「homepage/index.html」であり、こ のHTTPリ クエストがHTTPのバージョン1.0に従って作成されたものであること がわかります。また、必要に応じて付加情報も解釈します。 そして、返信要 求されたオブジェクト(情報)「/homepage/index.html」というファイルを見 つけ、その中身を読み出します。この例の場合、HTTPサーバに あるホームペー ジファイルの格納用ディレクトリの下にある「homepage」というサブディレク トリの下にあるファイル「index.html」ということになります。
サーバからの返答を待ってます。 返答はリクエスト送信に使ったTCP通信 ソケットで 受け取ります。

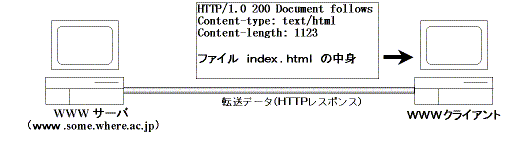
HTTPレスポンスを作成し、Webブラウザに送ります。 HTTPレスポンスは、返信要求のあったファイルの読み込みに 成功したので、そのリクエストステータスコードは200になります。 これにHTTPサーバが使うHTTPのバージョン番号、付加情報をつけたもの になります。
HTTP/1.0 200 Document follows Server: Microsoft Internet Server/4.0 Date: Mon, 8, Dec, 1997 19:17:05 GMT Content-type: text/html Content-length: 1123
続けて、空行を一つ送信した後に、ファイル「index.html」の中身を つけます。ですから、ファイル「index.html」の中身が
<HTML> <HEAD><TITLE>Test Page</TITLE></HEAD> <BODY> <H1>Welcome to My Home Page</H1> <P> Thank you very much for your accessing this homepage. </P> </BODY> </HTML>
ならば、HTTPサーバが作成するHTTPレスポンスは以下のようになります。
HTTP/1.0 200 Document follows Server: Microsoft Internet Server/4.0 Date: Mon, 8, Dec, 1997 19:17:05 GMT Content-type: text/html Content-length: 1123 <HTML> <HEAD><TITLE>Test Page</TITLE></HEAD> <BODY> <H1>Welcome to My Home Page</H1> <P> Thank you very much for your accessing this homepage. </P> </BODY> </HTML>
なお、行の折り返しは、CR(ASCIIコードにおいて十進数で13の文字)、 LF(ASCIIコードにおいて十進数で10の文字)をつなげたもので表します。
ファイル「index.html」が見つからなかったときは、 ステータスコード「403」を返します。
サーバからの返答を受け取ります。
ネットワーク接続を閉じ、待機状態になります。
HTTPレスポンスを解釈します。先頭行「HTTP/1.0 200 Document follows」よ り、このレスポンスHTTPのバージョン1.0をもとに作成され、「200」よりリク エストが成功したことがわかります。また、付加情報の「Content-type: text/html」より送り返されたデータは、テキストでその表現形式がHTMLであ ることが、また、そのサイズは「Content-length: 1123」より1123バイトであ ることがわかります。そして、要求したオブジェクト(情報)は一個の空行の 後に続くデータとなりますので、それを取り出して表示します。また、 ネットワーク接続を閉じます。

なお、この「index.html」の中に、例えば「<IMG SRC="images/logo.gif">」 のように画像データなどが含まれている場合は、ステップ1に戻って以下の HTTPリクエストをサーバに再び送ります。
GET /homepage/images/logo.gif HTTP/1.0 User-agent: Microsoft Explorer for Windows/3.0 Accept: text/plain Accept: text/html Accept: image/gif Accept: image/jpeg
このとき「<IMG SRC="images/logo.gif">」となっていても、 ファイル「index.html」のあった場所を基準にしてURIを 組み立てるので「/homepage/images/logo.gif」となります。