Biometric spoofing and anti-spoofing
Detection of fake facial videos | Generation and detection of fake reviews / fake news | Construction of a large high-quality dataset to improve the performance of fake facial image/video detection | Master faces: Wolf Attacks on Face Recognition Systems | Generating Adversarial Examples that are Resistant to Media Processing | Simultaneous face and voice conversion
Detection of fake facial videos
- D. Afchar, V. Nozick, J. Yamagishi, and I. Echizen, "MesoNet: a Compact Facial Video Forgery Detection Network", Proc. of the IEEE International Workshop on Information Forensics and Security (WIFS 2018), pp.1-7, December 2018, Preprint, Demo video, code
- Huy H. Nguyen, Junichi Yamagishi, and Isao Echizen, "Capsule-forensics: using capsule networks to detect forged images and videos", Proc. IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), 5 pages, (May 2019), Preprint, Demo video, code
- Huy H. Nguyen, Fuming Fang, Junichi Yamagishi, Isao Echizen,"Multi-task Learning For Detecting and Segmenting Manipulated Facial Images and Videos", Proc. of the BTAS 2019,8 pages,(September 2019) Preprint, Demo video, code
By training AI with large amounts of human-derived data such as faces, voices, and natural language, it has become technically possible to generate "synthetic media" such as facial images, voices, and text that can be mistaken for the real thing. While there are many possible applications for this technology that can enrich our society, there is also the possibility of fraud and information manipulation if it is misused. In particular, Deepfake video, in which the face in the video is replaced by another person's face, has become a social problem. In 2018, we presented the world's first CNN-based method for fake facial video detection. Since CNN-based detectors require multiple layers and an increase in the size of the layers in order to improve the accuracy of fake facial video detection, we have proposed a fake facial video detection method called Capsule-Forensics, which is a modification of the Capsule Network used for computer vision tasks. In addition, we have proposed a model that simultaneously determines the authenticity of fake facial video and estimates the tampering region using multi-task learning. We are currently working on further improvements to improve the accuracy and reduce the weight.

Principle of Capsule-Forensics
Detection of real and fake video
Reference
Generation and detection of fake reviews / fake news
- David Ifeoluwa Adelani, Haotian Mai, Fuming Fang, Huy H. Nguyen, Junichi Yamagishi, Isao Echizen, "Generating Sentiment-Preserving Fake Online Reviews Using Neural Language Models and Their Human- and Machine-based Detection", Advanced Information Networking and Applications (AINA 2020), pp.1341-1354, April 2020, Link
- S. Gupta, H. Nguyen, J. Yamagishi, and I. Echizen, "Viable Threat on News Reading: Generating Biased News Using Natural Language Models", Proc. of the NLP+CSS Workshop at EMNLP 2020, 11 pages, November 2020, Preprint
With the development of neural language models such as GPT-3 and BART, automatic generation of natural and fluent sentences is becoming easier and easier, and they are used for various purposes such as document classification and automatic summarization. On the other hand, there is a threat that neural language models can be misused to automatically generate fake reviews of products and services on e-commerce sites, or to automatically generate fake news on the Internet. We have devised a method to automatically generate a large number of fake reviews using a neural language model, using human reviews of products and services as a seed, while maintaining the positive/negative sentiment of the reviews. At the same time, we are investigating a method to detect the generated fake reviews. In addition, we are investigating a method to automatically generate a large amount of fake news that emphasizes the degree of bias, such as leftist/rightist, of news articles seeded with news articles created by humans, and a method to detect these news.
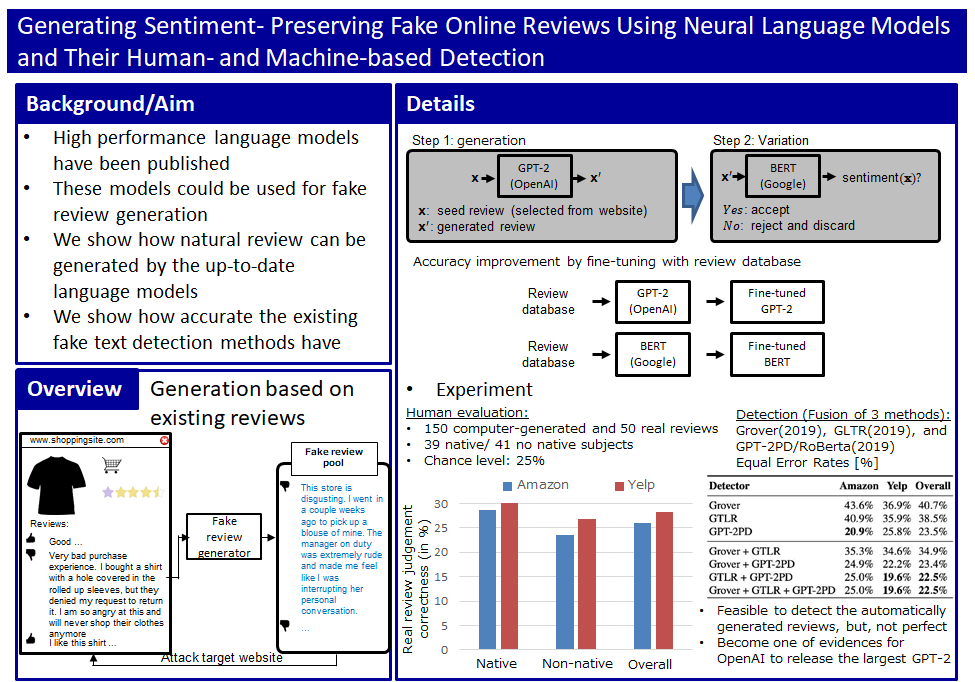
Generation and detection of fake reviews

Generation of fake (biased) news
Reference
Construction of a large high-quality dataset to improve the performance of fake facial image/video detection
- Trung-Nghia Le, Huy H. Nguyen, Junichi Yamagishi, Isao Echizen, "OpenForensics: Large-Scale Challenging Dataset For Multi-Face Forgery Detection And Segmentation In-The-Wild" ICCV 2021, accepted, October 2021, Preprint presentation video, dataset
Many fake facial image/video detection methods have been proposed, but in the past, models were built on the assumption that face detection had already been performed, and the input to the model was always a single detected face image. As a result, when there are multiple faces in an image, the model judges the authenticity sequentially after detecting each face image one by one, which is very inefficient. Recently, an object detection model has been proposed to detect multiple objects in an image at the same time, and we assume that fake facial image/video detection will become such a model in the future. Therefore, we decided to build a high-quality dataset for fake facial image/video detection and falsification region estimation that contains a large number of images with multiple faces in natural images, and constructed a dataset called OpenForensics, which consists of 115,000 images with 34,000 faces.
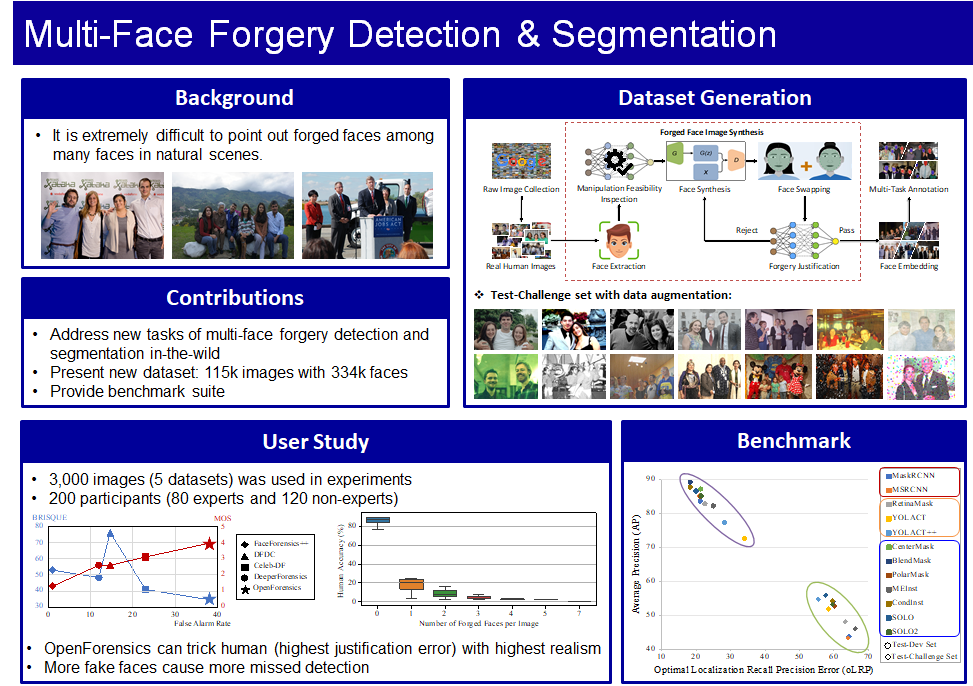
Overview of OpenForensics dataset
Reference
Master faces: Wolf Attacks on Face Recognition Systems
- Huy H. Nguyen, Junichi Yamagishi, Isao Echizen, Sebastien Marcel, "Generating Master Faces for Use in Performing Wolf Attacks on Face Recognition Systems", Proc. of the 2020 International Joint Conference on Biometrics (IJCB 2020) , 10 pages, Sept. 2020 Preprint
- Huy H. Nguyen, Junichi Yamagishi, Isao Echizen, Sebastien Marcel, " Master Face Attacks on Face Recognition Systems", Preprint
Due to its convenience, biometric authentication, especial face authentication, has become increasingly mainstream and thus is now a prime target for attackers. Presentation attacks and face morphing are typical types of attack. Previous research has shown that finger-vein- and fingerprint-based authentication methods are susceptible to wolf attacks, in which a wolf sample matches many enrolled user templates. In this work, we demonstrated that wolf (generic) faces, which we call "master faces," can also compromise face recognition systems and that the master face concept can be generalized in some cases. Motivated by recent similar work in the fingerprint domain, we generated high-quality master faces by using the state-of-the-art face generator StyleGAN in a process called latent variable evolution. Experiments demonstrated that even attackers with limited resources using only pre-trained models available on the Internet can initiate master face attacks. The results, in addition to demonstrating performance from the attacker's point of view, can also be used to clarify and improve the performance of face recognition systems and harden face authentication systems.
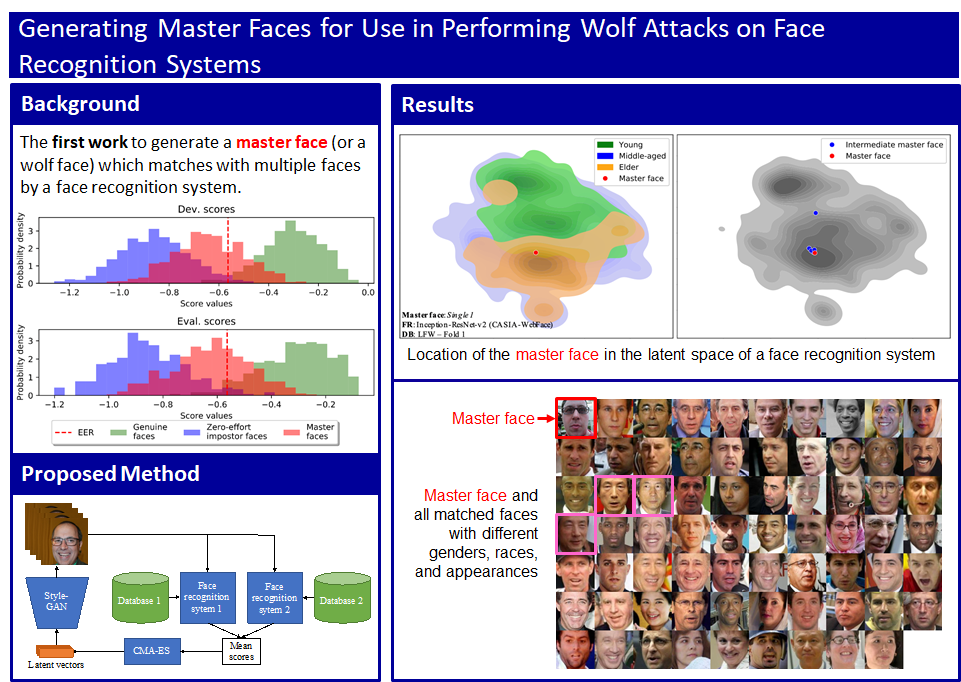
Overview of generating master faces
Reference
Generating Adversarial Examples that are Resistant to Media Processing
- Marc Treu, Trung-Nghia Le, Huy H. Nguyen, Junichi Yamagishi, Isao Echizen, "Fashion-Guided Adversarial Attack on Person Segmentation", Computer Vision and Pattern Recognition WORKSHOP ON MEDIA FORENSICS 2021, accepted, June 2021, Preprint, Presentation Video, code/dataset
There are cases in which the faces and figures of ourselves and others appear in the photos and videos we share on social networking sites, etc. Analyzing these photos and videos with machine learning models may violate the privacy of the subject and the photographer. In order to prevent third parties from inadvertently analyzing contents shared in cyberspace, including such threats, we studied a method for generating adversarial examples for images. As a requirement of the adversarial examples generated by our method, it is important to have both transparency to reduce the discomfort in appearance and robustness to maintain the effectiveness as an adversarial example against media processing such as JPEG when photos are shared. As a concrete study, we take person segmentation as an example of analysis, and by changing the texture of the clothing area of the target image, we can disable person segmentation while maintaining transparency, and achieve a robustness against JPEG compression. We proposed a Fashion-Guided Adversarial Attack with a certain robustness against JPEG compression.
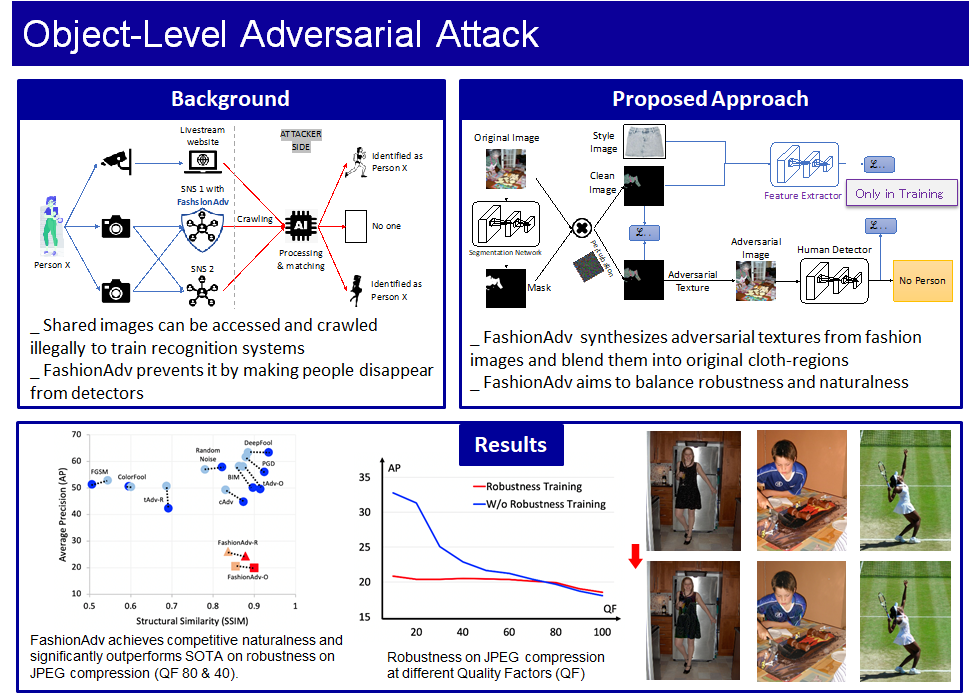
Overview of Fashion-Guided Adversarial Attack
Reference
Simultaneous face and voice conversion
- Fang, Fuming, et al. "Audiovisual speaker conversion: jointly and simultaneously transforming facial expression and acoustic characteristics." ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2019.
- Fang, Fuming, et al. "High-quality nonparallel voice conversion based on cycle-consistent adversarial network." 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2018.
Although many techniques have been proposed to convert a person's face and voice into another person's face and voice, until now, face and voice conversion have been treated as separate processes, despite the strong correlation between facial expressions and voice. Therefore, we proposed a method for simultaneous conversion of face and voice. The conversion model first extracts the facial and speech features of the source speaker. Next, the extracted facial and acoustic features are input to the simultaneous conversion model, and the features are fused together. Finally, the transformation is performed by converting the output features back to the face image and audio waveform of the target speaker.
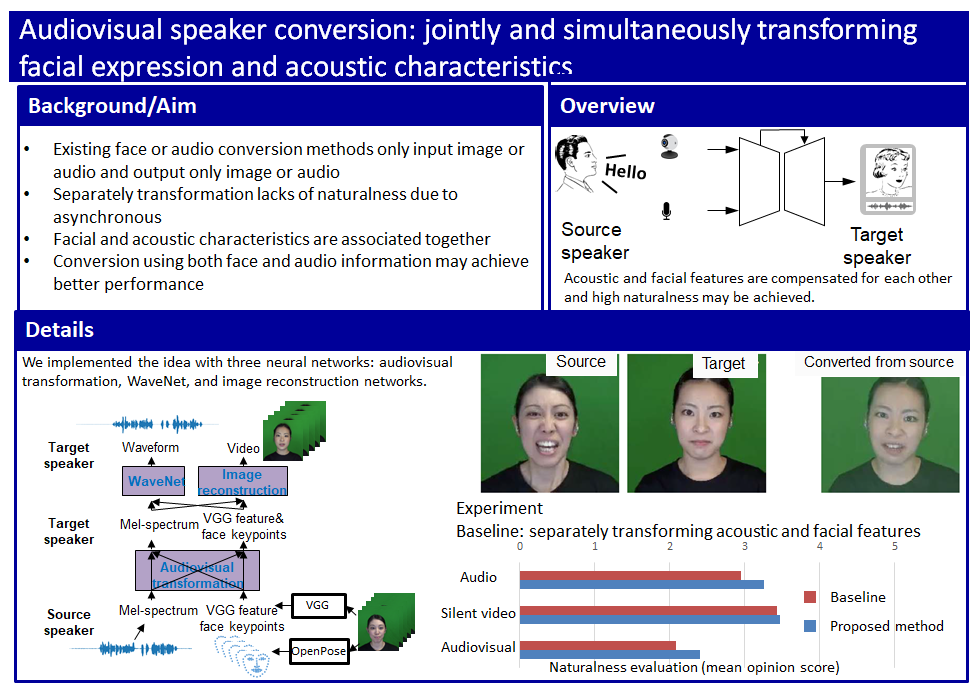
Principle of simultaneous face and voice conversion