![]()
データベース処理
![]()
最近は、IT 、POSとかインターネットとかのおかげで、大量のデータが楽に集められるようになりました。顧客とか文書とかの情報が大量にデータベースに蓄えられて、それを楽に検索できるようになったわけです。データベースソフトも、機能のいいものが出てきました。SQL という共通のデータ処理言語が普及して、1つのデータベース処理ソフトを作ると、どのデータベースでも使えるという便利な世の中になりました。これで、個人用の住所録データを変換するソフトから、大企業の顧客管理や受注品、あるいは工程管理をするソフトまで、いろいろなことが共通のソフトでできるようになったわけです。
この SQL という言語は、基本的なデータベースを処理する命令を集めたものです。適用範囲も広く、これを覚えるだけでどのデータベースも扱えるようになり、かつ、だいたいの処理は SQL を使って行えます。だいぶん便利なものなのですが、SQL にも苦手なものはあります。ちょっと例を見てみましょう。
今、トラックとその行き先がセットになったデータがデータベースに入っているとします。トラック1,...,n があって、それらの目的地が都市1,...,m のどれかであるとしましょう。各データは、トラックの名前 i と都市の名前 j の組になっています。こんな感じです。
トラック 1 -> 都市 1, トラック 2 -> 都市 4, トラック 3 -> 都市 1,
トラック 4 -> 都市 1, トラック 5 -> 都市 3, トラック 6 -> 都市 2, ....
このデータベースを検索すると、任意のトラック、例えばトラック 5 がどこへ行くか調べることができます。では逆に、ある都市 i にいくトラックはどれかを調べたかったら、どうなるでしょうか?普通に SQL を使うと「行き先が都市 i であるトラックを全部見つけなさい」という命令を使います。索引をつけていなければ、全部のデータを調べることになります。全ての都市について調べるとなると、n × m 個のデータを検索することになります。例えばトラックが100万、都市が10万あるような大きなデータベースであれば、この検索はおよそ20分はかかります。コンピューターのメモリが少なければ、1時間以上かかります。トラックと都市の例なら、こんな大きなデータはありえないと思いますが、工場の工程管理などのデータベースでは、これくらいの規模のものが出てきます。
これを、検索を普通のプログラムで行うことにして、アルゴリズムを工夫すれば、全部のデータを一回だけ見るだけですむようになります。やり方は以下のとおり。
------------------
1. 各都市 i 用の箱を用意する。(箱を m 個用意する)
2. データを最初から順番に見て、そのトラックの行き先の都市の箱にデータを入れる。つまり、行き先が都市 i ならば、都市 i の箱に入れる。
3. データを順々に見て、この操作を続ける。
------------------
この作業が終わると、各箱に、その箱の都市が行き先になっているトラックのデータが入っています。ここでは「箱」という言葉を用いて説明していますが、コンピューターが実際に箱を用意するわけではなく、箱を用意するのと同じ仕組みのプログラムを作る、ということです。
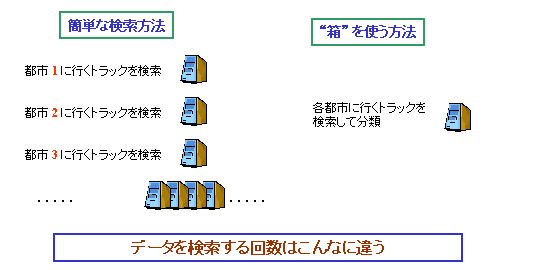
この作業では、1つのデータを一回しか見ませんから、データを見る回数は n 回。SQL の簡単な方法よりも m 倍早くなります。先ほどの、トラック 100万台、都市が10万の例では、10万倍速くなるわけです。
この例は、教科書的な問題で、少々アルゴリズムを勉強すれば思いつく方法です。より高度なアルゴリズム技術を用いれば、より複雑な検索問題に対しても、1日かかる計算を10分程度に高速化できる可能性もあるわけです。
![]()