Task Description: NTCIR Workshop 2
| The 2nd NTCIR Workshop was OVER. |
| For the current NTCIR Workshop (the latest in the series of NTCIR Workshops), visit
|
| The 2nd NTCIR Workshop was OVER. |
| For the current NTCIR Workshop (the latest in the series of NTCIR Workshops), visit
|
 Chinese Information Retrieval Task: Chinese monolingual IR; English-Chinese cross-lingual IR; to investigate
the search effectiveness of systems that search a static set of Chinese
documents using new Chinese and/or English topics. The details of Chinese
IR task could be referred to the http://lips.lis.ntu.edu.tw/cirb/events-1.htm The related information is also in the same web site: http://lips.lis.ntu.edu.tw/cirb/index.htm We are sorry that some information is in Chinese only. We will create
the English version as soon as possible.
Japanese & English Information Retrieval Task: Japanese and/or English monolingual IR; cross-lingual IR of single language
documents and mixed-language documents of English and Japanese by Japanese
and/or English topics; to investigate the search effectiveness of systems
that search a static set of documents
Text Summarization task : Automatic text summarization of Japanese texts
Chinese Information Retrieval Task: Chinese monolingual IR; English-Chinese cross-lingual IR; to investigate
the search effectiveness of systems that search a static set of Chinese
documents using new Chinese and/or English topics. The details of Chinese
IR task could be referred to the http://lips.lis.ntu.edu.tw/cirb/events-1.htm The related information is also in the same web site: http://lips.lis.ntu.edu.tw/cirb/index.htm We are sorry that some information is in Chinese only. We will create
the English version as soon as possible.
Japanese & English Information Retrieval Task: Japanese and/or English monolingual IR; cross-lingual IR of single language
documents and mixed-language documents of English and Japanese by Japanese
and/or English topics; to investigate the search effectiveness of systems
that search a static set of documents
Text Summarization task : Automatic text summarization of Japanese texts
 The languages used in the IR subtasks are specified as "Topic Language (C, J or E) - Document Language (C, J or E)", where C stands for Chinese, J for Japanese and E for English.
The languages used in the IR subtasks are specified as "Topic Language (C, J or E) - Document Language (C, J or E)", where C stands for Chinese, J for Japanese and E for English.
 Chinese Information Retrieval Task :Chinese monolingual IR; English-Chinese cross-lingual IR; to investigate
the search effectiveness of systems that search a static set of Chinese
documents using new Chinese and/or English topics.
Chinese Information Retrieval Task :Chinese monolingual IR; English-Chinese cross-lingual IR; to investigate
the search effectiveness of systems that search a static set of Chinese
documents using new Chinese and/or English topics. (1) Task Description
The Chinese Text Retrieval Tasks focus on the evaluation of an IR system
in retrieving Chinese texts based on topics in either Chinese or English.
The training set and the testing set of Chinese Text Retrieval Tasks are
selected from the Chinese Information Retrieval Benchmark 1 (CIRB-1). The
CIRB-1 consists of three parts: 1) Document Set; 2) Topic Set; and 3) Relevance
Judgment. Now, the Document Set contains 132,173 news articles from 5 news
agencies in Taiwan, the Topic Set contains 50 topics in a form of user's
information need from briefs to details, and the Relevance Judgment consists
of the related documents to the various topics.
 Chinese IR Task (The Monolingual IR (C-C Task))
English-Chinese IR Task (The Cross-Lingual IR (E-C Task))
As soon as possible: Submit an application.
August 31, 2000: CIRB-1-CH CD (132,172 documents and 50 Chinese topics) will be distributed
to the participants of Chinese IR Task, and CIRB-1-EN CD (132,172 documents
and 50 English topics) will be distributed to the participants of English-Chinese
IR Task.
October 20, 2000: Search results and system description forms submission.
January 10, 2001: Results of Relevance Assessments will be distributed to the participants.
February 12, 2001: Papers for the working-note proceedings submission.
March 7-9, 2001: Workshop meeting at NII, Tokyo, Japan.
March 16, 2001: Camera-ready copies for the proceedings.
Japanese & English information retrieval task: Japanese and/or English monolingual IR; to investigate the search effectiveness
of systems that search a static set of documents using new search topics.
Both automatic systems and interactive systems are welcome.
Chinese IR Task (The Monolingual IR (C-C Task))
English-Chinese IR Task (The Cross-Lingual IR (E-C Task))
As soon as possible: Submit an application.
August 31, 2000: CIRB-1-CH CD (132,172 documents and 50 Chinese topics) will be distributed
to the participants of Chinese IR Task, and CIRB-1-EN CD (132,172 documents
and 50 English topics) will be distributed to the participants of English-Chinese
IR Task.
October 20, 2000: Search results and system description forms submission.
January 10, 2001: Results of Relevance Assessments will be distributed to the participants.
February 12, 2001: Papers for the working-note proceedings submission.
March 7-9, 2001: Workshop meeting at NII, Tokyo, Japan.
March 16, 2001: Camera-ready copies for the proceedings.
Japanese & English information retrieval task: Japanese and/or English monolingual IR; to investigate the search effectiveness
of systems that search a static set of documents using new search topics.
Both automatic systems and interactive systems are welcome. (1) Task Description
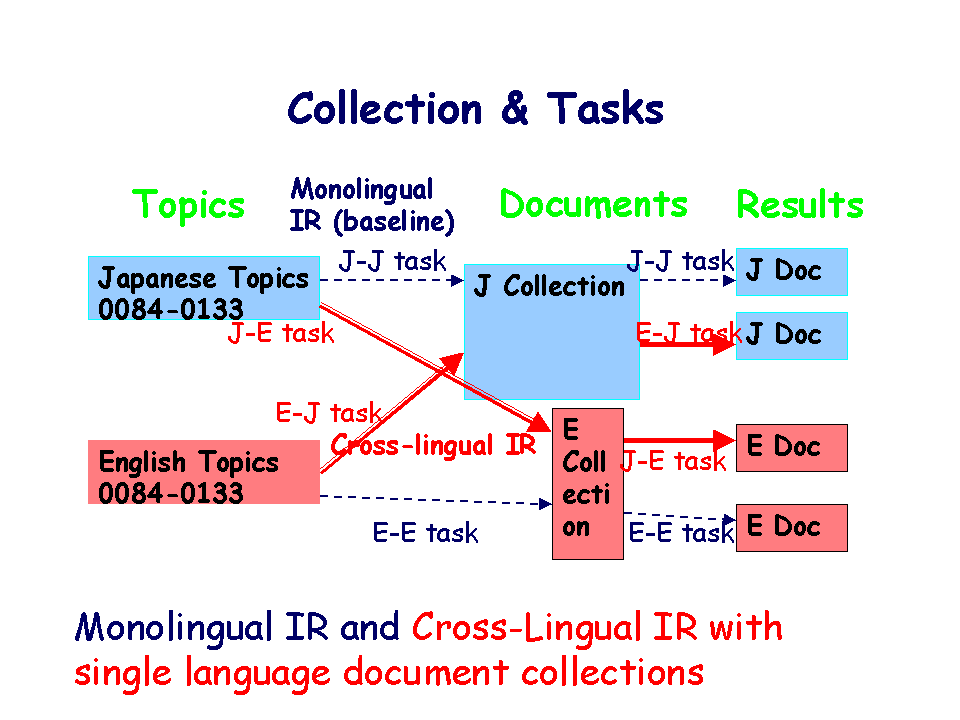
There are two sub-categories, Monolingual IR and Cross-Lingual IR.
The Monolingual IR includes
The Cross-Lingual IR includes
The relationship of tasks, topics, and documents are shown below.
  |
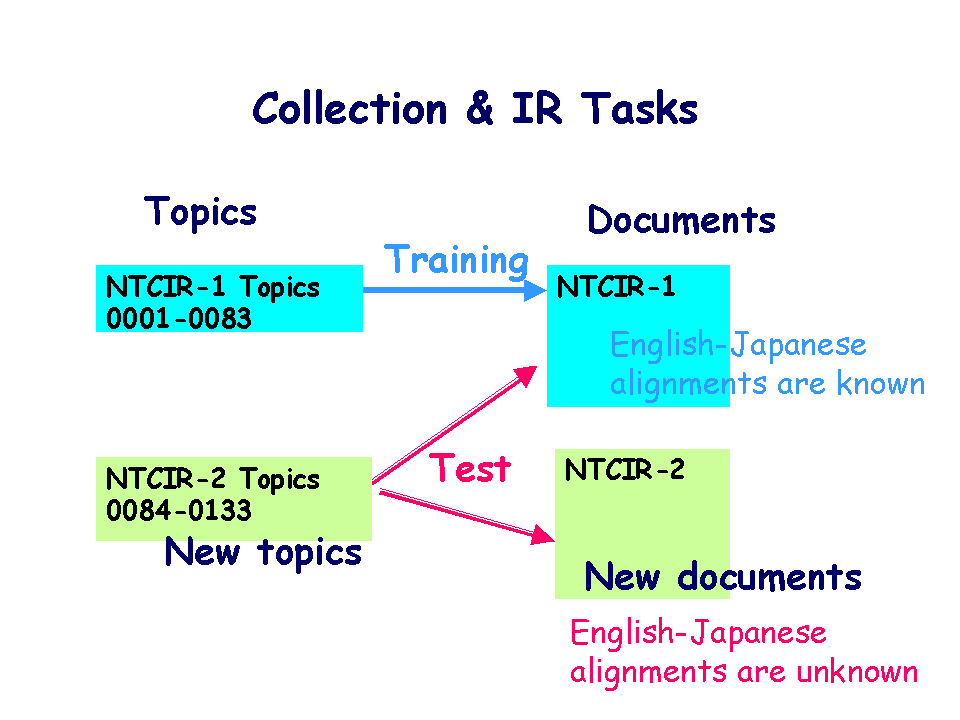
"Test Collection 1 (NTCIR-1)" is used for training. NTCIR-1 contains
more than 330,000 documents, 83 topics, and their relevance judgments.
More than half of the documents are English-Japanese paired (document alignments).
English documents and their paired Japanese documents share the same document
ID's (ACCN's), therefore the alignments between English and Japanese documents
are known from the document ID's and usable for training, including constructing
dictionaries and knowledge-bases for cross-lingual IR.
New collection NTCIR-2 (preliminary version) CD-ROM will be distributed to the participants in August, 2000. It contains new ca.400,000 documents and new 50 topics. For the test, to investigate the search effectiveness of the retrieval of the documents of NTCIR-1 and 2 by new 50 topics in the NTCIR-2. The results will be submitted as the ranked top 1000 documents retrieved for each topic. The format for the results submission is shown in Sample Home.
The relationship between the training and test sets is as below;
 |
Topics are the written statements of users' search requests. Queries (search
statements) can either be constructed automatically from the topics, or
manually. In the case of automatic query construction the participants
must submit the results of the searches using only "DESCRIPTION"
fields of the topics as the mandatory runs. As optional runs, any fields
of the topics can be used to construct queries. In the case of manual query
construction, any fields of the topics can be used in the search.
A participant can submit the results of more than one run. When more than one set of search results will be submitted, please assign the priorities.
Human assessors do relevance assessments against the submitted search results. The organiser (We) will calculate recall/precision and related measures for all systems using an evaluation program and return individual results to each participant. The median of each measure for each topic among all submitted results will be also informed. These results will be included in the Workshop proceedings as an appendix. We use TREC's evaluation program, which is available from the ftp site of the Cornell University.
Training Set
"E Collection (clir/ntc1-e1.tgz)" and "J Collection (mlir/ntc1-j1.tgz)" in the NACSIS Test Collection 1 (NTCIR-1) CD-ROM can be used as training data sets. The document data set which is similar to "JE Collection (adhoc/ntc1-je1.tgz)" is not used in the NTCIR Workshop 2. Please give attention to that. The training topics in the NTCIR-1 (topics.tgz) are in Japanese. Use the relevance judgments included in the "E Collection (clir/ntc1-e1.tgz)" and "J Collection (mlir/ntc1-j1.tgz)"
Documents in the NTCIR-1 were part of the documents extracted from "NACSIS Academic Conference Paper Database". These are author abstracts of the papers presented at the conferences hosted by 65 academic societies in Japan. More than half of the documents are produced as English-Japanese paired (Document level alignments). "J Collection" contains Japanese documents and was constructed by extracting Japanese parts of the documents from the original database and "E Collection" contains English documents. Most of the documents in the "E Collection" have the equivalent documents in "J Collection" but some do not. For several cases, the relevance judgments are different between paired English and Japanese documents since the detailed expressions are different between them and the difference affected the judgments.
The equivalent pairs of documents in "E Collection" and "J Collection" share the same ACCN's (document ID's). These alignments are usable for the training, and constructing bilingual lexicons or knowledge bases used for cross-lingual IR.
ATTENTION! Since the formats of the ACCN fields are different in the NTCIR-1 and NTCIR-2, the ACCNs in the NTCIR-1 shall be changed as following;
Test Set
Documents in the J Collection and E Collection of NTCIR-1 and NTCIR-2 are used for the test purpose. The new document set, NTCIR-2 (preliminary version) also contains J Collection and E Collection. The test topics are both in Japanese and English. Documents in the NTCIR-2 contains two subfiles; (1) extended summaries of Grant-in-Aid research report (ca.300,000 documents), and (2) author abstracts of conference papers (ca.100,000 documents). About 25% of (1) and more than half of the (2) are Japanese-English paired (document alignments) but the alingments are not announced by results submission. Average length of the documents in the (1) are about three times longer than the documents in the NTCIR-1.(Statistics are available at http://research.nii.ac.jp/ntcir/workshop/length-en.html)
Segmented Japanese texts
Segmented Japanese texts are available as well as non-segmented ordinary Japanese texts for both Japanese documents and Japanese topics in the NTCIR-1 and NTCIR-2; in the segmented texts, each sentence is segmented into terms and term components (similar to phrases and words); use of this data set is optional; the purposes are (1) to enhance the cross-system comparison by providing a baseline of Japanese text segmentation, (2) to encourage the participation from non-Japanese research groups.
As index terms,
For more information about data and samples, please consult Data Home and Sample Home.
for each submitted result set for each topic and the mean value over all topics. The percentage of the effectiveness of the cross-lingual retrieval to the monolingual retrieval is also calculated. These will be returned to each participant.
We would like to emphasise here that the aims of the Workshop are to provide a forum for IR researchers interested in comparing results, and exchanging ideas, experiences, or opinions in an informal atmosphere, and to encourage research in IR and cross-lingual IR by providing a test collection. Therefore we expect that various approaches will be proposed and tested in this workshop, and that this workshop encourages intensive discussion through the mailing list of participants and at the Workshop meeting in March, 2001. Also if there will be an request to have additional discussion meetings or round-table meetings, we are happy to organise them. At the same time, we would also like to improve the quality of the test collection and explore the possibility of the resources available to evaluation of various IR systems based on the feedback, comments, advise, leads from participants.
For example, it is expected to have further insights on Japanese text retrieval regarding the following points. These are examples of the interests and not limited to. Many researches with various approaches are expected to be proposed and tested in this Workshop.
(i) Appropriate algorithms and parameters for Japanese text retrieval
In the NTCIR Workshop 1, the algorithms and parameters, which are known to be effective on English text, were applied to Japanese texts. It was partly because the shortness of the training period. Various sectors would be interested in "the good algorithms and parameters for Japanese text retrieval", or "are the algorithms which are good to English texts the best for Japanese texts?". Various challenges are expected.
(ii) Relationship between text segmentation and retrieval algorithms
One of the characteristic points of the Japanese texts is that there is no explicit boundaries between words in the sentences. Therefore many researches have been focused on the segmentation of Japanese texts. Someone said that the bi-gram is the best, and others said the word- and phrase-based indexing is the best. Each system uses each segmentation and each algorithm, thus the cross-system comparison becomes complicated. Moreover the effectiveness of the word- and/or phrase-based indexing may affected by the size of the lexical resources available and the oversea participants tended to be suffered by the disadvantage of the availability of the lexical resources. therefore the segmented Japanese texts of documents and topics are prepared for this Workshop.
The purpose of the segmented Japanese texts are; (1) to encourage the participation from non-Japanese research groups, (2) to investigate the effects of the segmentation methods on the search effectiveness, and (3) to encourage the comparison of the retrieval algorithms minimizing the affects from the segmentation. The use of the segmented texts is optional, but we would like to encourage to use them as a baseline.
The problems of the segmented texts include; they are not usable to examine the following issues, (1) the effect of the tuning of the segmentation methods according to the documents to be retrieved, (2) the effect produced from the good combination of the segmentation and retrieval algorithms, (3) the index structure like pat trie not depending on the segmentation. For canceling the effects of these issues as much as possible, we would like to use final query term lists (that include terms expanded from original query term lists) as a clue for measuring the effect. If you don't have problem on submitting these lists, we would like to request you to submit final query term lists with your retrieved results. Since this request is only volunteer base, you may not submit them. Regardless of these disadvantages, we prepared them as one of the attempts to investigate the characteristic aspects of the Japanese text retrieval. Further comments, discussion are welcome.
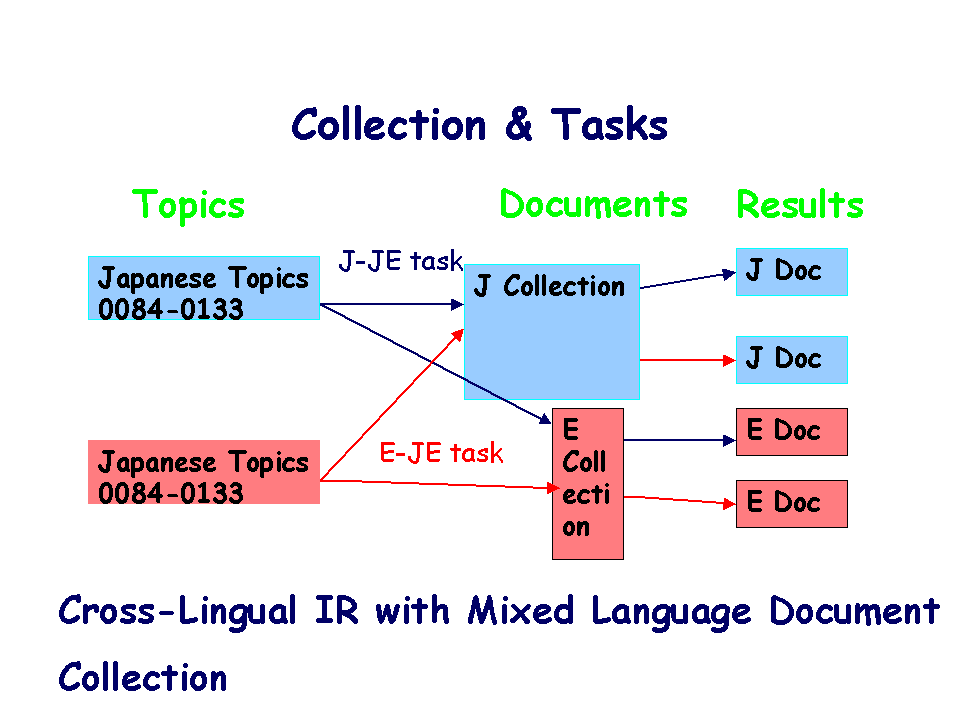
(iii) Retrieval of mixed-language texts and English terms in Japanese texts
The document collections, including web documents, produced in Japan are naturally Japanese and English mixture -- Some English documents are produced as a paired documents with Japanese; some are summaries of sets of Japanese documents; others are produced their own. Moreover Japanese documents naturally contain English terms with original spellings or as transliterated forms using Japanese KATAKANA characters. Such English terms are often newer concepts or specific technical terms which are important as search keys but hardly listed in the ordinary lexical resources like dictionaries and thesaurus. What kind of approaches will be effective for such environment of Japanese documents? Further insight on the matter is expected to be found through the discussion in this Workshop.
In the NTCIR Workshop 1, the "JE Collection", which containing many English-Japanese paired documents in the ad hoc IR task. However, there were not so many challenges on the matter. It was mostly because the explanation of the data was insufficient. Therefore, in order to simplify the problems, we set the different tasks of (1) monolingual IR, (2) cross-lingual IR using single language documents, and (3) retrieval of mixed-language documents. Various challenges are welcome.
(iv) Application for interactive systems
Interactive systems are also welcome. Many proposals and examination on the applicability of the laboratory-type testing to interactive systems are expected.
Document types and the future
This NTCIR Workshop uses scientific documents once more because we need the test data for the NTCIR-1 Collection, which was used in the previous Workshop. The features are;
One of the characteristic aspects of the NTCIR Workshop was Japanese-English paired scientific documents and it contains challenging issues like technical terms or new concepts. For the next and future we would like to enhance the variety of text types including fulltext of scientific papers, newspaper articles, patent documents, web documents, images, etc. as well as other challenging issues to evaluate the various technologies to support the usage of the information in the documents. Any comments, opinion, discussion, leads, advises on these matters are always welcome.
As soon as possible: Submit application. Deadline extended.
NTCIR-1 are available to those who have returned required forms.
For Text Summarization: application deadline may vary. announce later.
August 10, 2000: NTCIR-2 CD (new documents and fifty topics) will be distributed to Japanese
& English IR task participants.
September 18, 2000: Search results and system description forms submission (Japanese &
English IR task)
January 10, 2001: Relevance assessments for the new topics will be distributed to the participants
February 12, 2001: Papers for the Working-note proceedings
March 7-9, 2001: Workshop meeting at NII, Tokyo, Japan.
Day 1: Open to public, Days 2-3: Active participants only
March 16, 2001: Camera-ready copies for the proceedings
The language for the proceedings and the Workshop meeting is English.
(Contact Person: Task Chair: Noriko Kando kando![]() )
)
Text Summarization task: automatic text summarization of Japanese texts.
The aim of the text summarization task is two-fold. The first is to collect qualified text data for summarization in Japanese. We will have newspaper articles summarized by hand, and make them available for research purpose. We will include not only economic news articles but also articles in other domains in the newspaper.
We are planning to collect two types of summaries from the newspaper articles. The first type is extract-type of summaries, where we regard a set of important sentences in the articles as its summary. We ask the annotators to extract important sentences from each article. The second type is abstract-type summaries. We ask the annotators to summarize the original articles without worrying about the unit of sentences, and focus upon trying to obtain the main ideas of the articles. We are going to use several hundred articles for both types of summaries. We would like to make at least a part of the results available to the participants of the task, and use the rest for the evaluation task.
The second is to evaluate text summarization systems. We have been investigating
how to evaluate summarization systems, and one of the possible evaluation
methods is an extrinsic evaluation where the results of the summarization
systems are used to conduct information retrieval tasks.
(Contact Person: Task Chairs: Manabu Okumura (oku![]() ) or Takahiro Fukushima
) or Takahiro Fukushima
(fukusima![]() ).
).
[Japanese] [NTCIR Home][Workshop Home] [Data Samples] [Top]
