1.4.2 Codd's examples
1) Find all the part numbers of parts being supplied.
(1-11)
Dfreq p# supply.d | Dproj p#
As Dfreq adds
count field, we need
Dproj to remove it.
If you want more readable output, you may use
Dpr.
(1-12)
Dfreq p# supply.d | Dpr -p p#
If you don't mind duplication, use just
Dproj.
(1-13)
Dproj p# supply.d
You can remove duplication with the next commands.
(1-14)
Dproj p# supply.d | Dsort p# | Dbundle p#
But, using Dfreq is generally faster.
2) Find the part numbers, names and quantities on hand where quantity on hand (qoh) is less than 25.
(1-15)
Dselect FIELD qoh:n LT CONST 25 -- part.d | Dproj p#,pname,qoh
Dselect uses
D specific language
Dl
for the condition.
FIELD qoh:n
means the field qoh evaluated as numeric.
Input file name is part.d and
-- is the end token to mark the end of
Dl expression.
You may wirte
(1-16)
Dselect qoh:n LT 25 part.d | Dproj p#,pname,qoh
The keywords FIELD
and CONST
may be omitted,
because a non reserved word at the top of the expression
is interpreted as a field name, and a non reserved word after
comparison or assignment operator as a constant.
But, it is recommendable to use keywords FIELD or
CONST whenever you are not sure.
The end token -- can be omitted
where the filename (part.d in this case) is not a
reserved word of the Dl.
Note also that Dl is always case sensitive.
3) Same query as former one but the result ordered by increasing weight (major order) and decreasing qoh (minor order).
(1-17)
Dselect FIELD qoh:n LT 25 part.d | Dproj p#,pname,qoh | Dsort weight:n,qoh:nr
Dsort takes key field list
with key flags.
The flag n means "numeric" and
the r
means "reverse order".
4) Find the part numbers, part names, and quantities on hand where
quantity on hand is less than 25, retrieving no more than five
elements.
(1-18)
Dselect FIELD qoh:n LT 25 part.d | Dproj p#,pname,qoh | Dextract 1-5
Dextract extracts
D-records by record positions.
You may use Dselect instead.
(1-19)
Dselect FIELD qoh:n LT 25 part.d | Dproj p#,pname,qoh | Dselect NR LE 5
5) Find the supplier numbers of those suppliers who supply the part with part number 3.
(1-20)
Dselect p# == 3 supply.d | Dfreq s# | Dproj s#
6) Find the supplier names of those suppliers who supply the part
with part number 3.
(1-21)
Dselect p# == 3 supply.d | Dfreq s# | \
Djoin -c s# - supplier.d | Dproj sname
Djoin is the key operation here.
Frequently used option -c (on core join) allows
input files not sorted in the key field order.
Note that the first input file of Djoin is piped
from the previous command and the second input file is
supplier.d.
Next commands produce same result.
(1-22)
Djoin -c s# supplier.d
supply.d | \
Dselect p# == 3 | Dfreq sname | Dproj sname
In most cases, the first one is faster,
because Djoin tends to produce a big file,
selection first and join later is better.
7) Find the supplier numbers of those suppliers who have the same
location (loc) as supplier Jones.
(1-23)
Dselect sname == Jones supplier.d | Dfreq loc | \
Djoin -c loc - supplier.d | Dproj s#
The operation structure is same as (1-22),
but it joins the first step result with the same D-file (supplier.d).
For this reason, analogous solution of (1-22)
(1-24)
Djoin -c loc supplier.d supplier.d | \
Dselect sname == Jones | Dfreq s# | Dproj s#
does not work for the question 7.
This is due to the fact that Djoin takes no heed
to the duplication of field names.
There is another solution using repeating fields.
(1-25)
Dsort loc supplier.d | Dbundle loc | \
Dselect sname INCL Jones | \
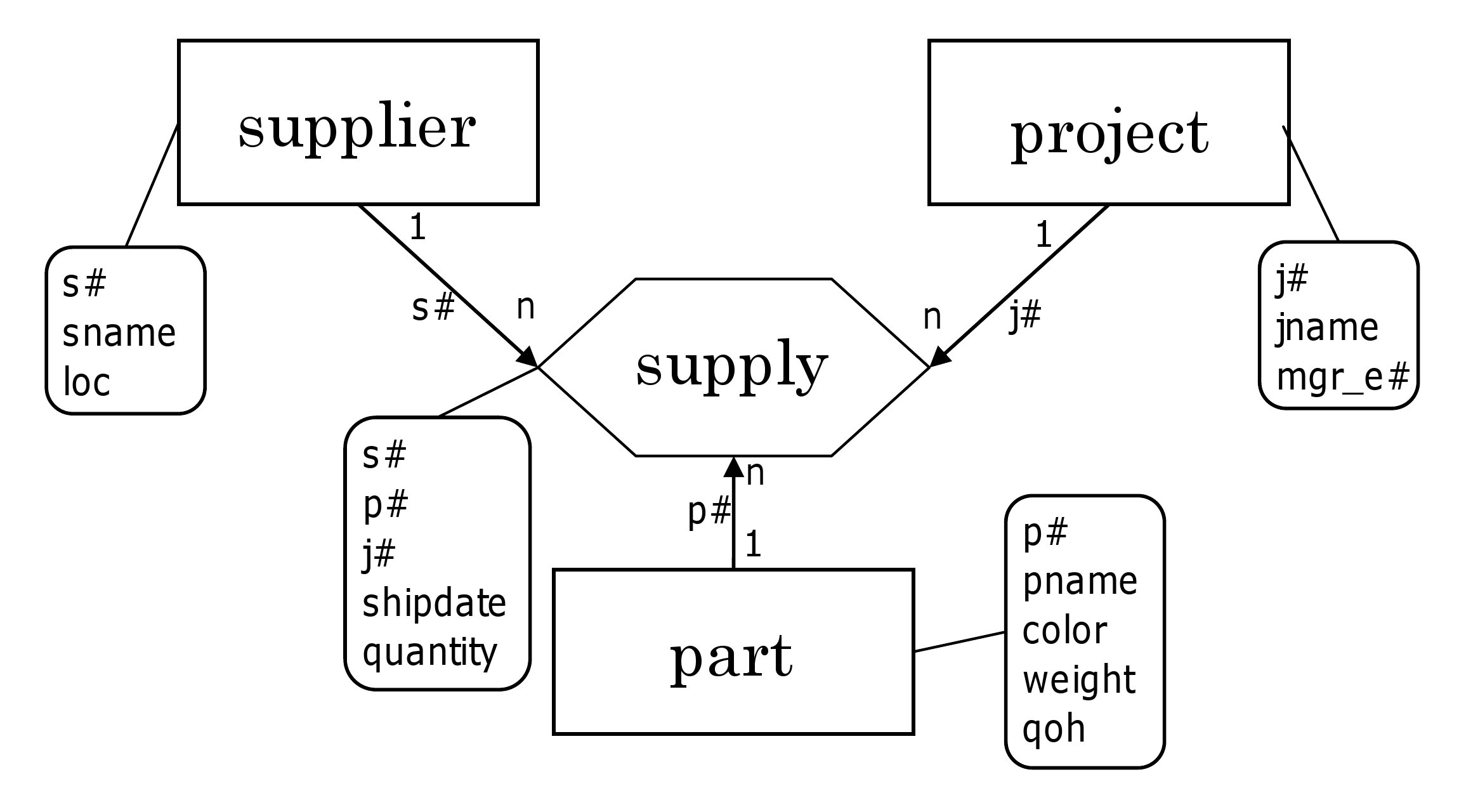
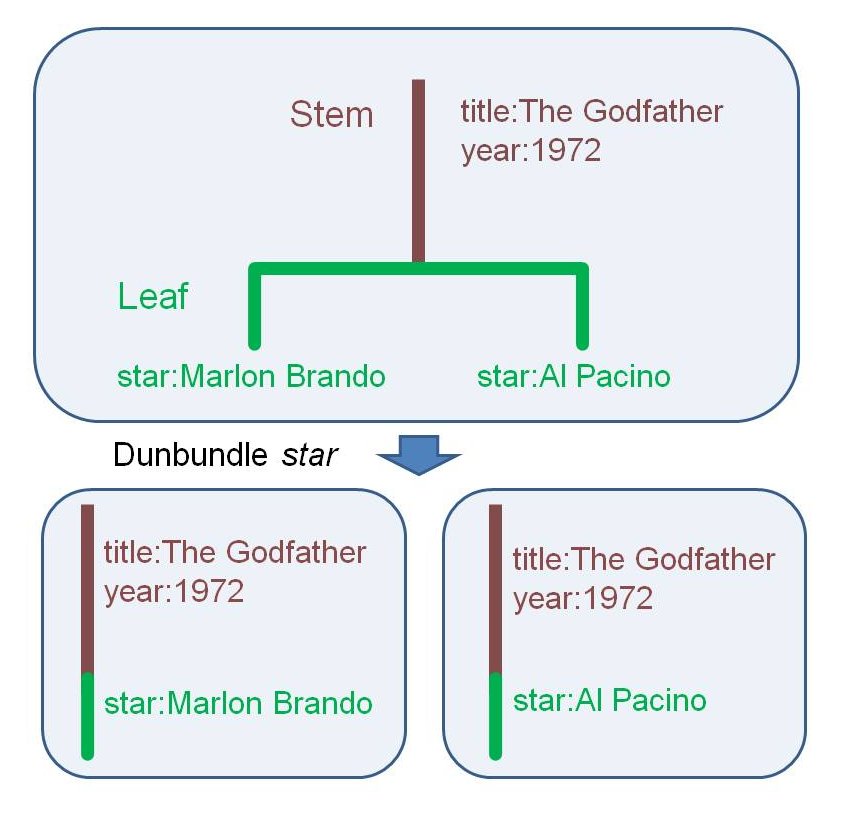
Dunbundle "^loc" | Dproj s#
Dbundle and
Dunbundle provides a way
of grouping and ungrouping.
Dbundle groups adjacent same key
(here "loc")
value records.
As same key records must be adjacent, we use
Dsort first.
Next, Dselect select
the group which includes Jones.
Note that
INCL
operator is used here.
Because sname field
(as well as s#) repeats
in this bundled record,
sname == Jones
does not work.
Dunbundle
separates grouped fields to original records.
The parameter ^loc means the fields except
for loc form the
leaves to be separated.
8) Find the supplier numbers of suppliers who supply a part other than part number 3.
This is negation of the question 5.
(1-26)
Dselect p# NE 3 supply.d | Dfreq s# | Dproj s#
9) Find the supplier numbers of suppliers who do not supply part number 3 (and may not supply any part at all at this time).
(1-27)
Dsort s# supply.d | Dbundle s# | \
Djoin -o 1x -c s# supplier.d - | \
Dselect NOT p# INCL 3 | Dproj s#
The first Dsort is
just a preparation to use the Dbundle.
The Dbundle groups adjacent same key value records
to one record.
In this case, the output is supply table for each supplier
number (s#).
Next Djoin attaches this
supply table to the supplier record.
The option -o 1x tells Djoin to output
all the records from the first file (supplier.d) regardless
of matching result.
(In fact, this option may be omitted, because it is
the default when -c option is in effect).
This Djoin is necessary to keep suppliers who
does not supply any part.
The condition of Dselect
uses INCL operator
as the record has multiple p# fields,
and NOT operator negates the result.
10) Find the names and locations of all suppliers, each of whom supplies all projects.
If you know there are seven projects in all,
you can check if a supplier supplies allprojects
only with the file supply.d.
(1-28)
Dfreq s#,j# supply.d | Dbundle s# | \
Dselect COUNT j# == 7 | \
Djoin -c -o 11 s# - supplier.d | Dproj sname,loc
The Dfreq counts
s#
and j# combination in
supply.d.
But, the field count is not important here.
After Dbundle by
s#,
records that have seven j# fields
provides all the projects.
Then, with Djoin s#,
sname
and loc are attached to the
selected s#.
The option "-o 11" tells
Djoin to output only matched records.
With this option we can exclude s# not found
in supplier.d.
(Yes, this is an error case and there should not be).
When we do not know the total number of suppliers,
we need some more procedures.
(1-29)
Dfreq s#,j# supply.d > tmp.d
Djoin "" supplier.d project.d | \
Djoin -c s#,j# - tmp.d | \
Dbundle s#,sname,loc | \
Dselect COUNT count == COUNT j# | Dproj sname,loc
The first step is same as the previous one.
We store it to a temporary file.
The second step Djoin joins
supplier.d
and project.d with null key-field-list.
It is cross production operation.
All the combination of records in
supplier.d and
project.d is produced.
In the third step, the temporary file is attached
to this cross production.
In this output, when the supplier does not supply
to the project, the count field is missing.
In the fourth step, Dbundle groups records by
suppliers.
The parameter needs s# and its dependent fields
(sname and
loc), otherwise the output
has repeated sname
and loc.
In the last steps,
COUNT j# is
always the number of projects in all,
while COUNT count
is actual number of projects that the supplier supplies.
11) For each project obtain as a triple the project number, project name and supplier location for all suppliers who supply that project.
(1-30)
Djoin -c j# supply.d project.d | \
Djoin -c s# - supplier.d | \
Dfreq j#,jname,loc | Dproj j#,jname,loc
First, attach project information to
supply.d,
then attach supplier information to it.
Dfreq extract the triple.
12) Find the names and locations of all suppliers who supply at least those projects supplied by supplier Jones.
It will take two steps.
First, we make a set of project numbers to which
Jones supplies.
(1-31)
Dselect sname == Jones supplier.d | \
Djoin -c s# - supply.d | \
Dfreq j# | \
Dproj j# | \
Dbundle "" | \
Drename j#:j#Jones > tmp.d
The project number list is renamed as j#Jones,
as it is tested against each supllier in the next step.
(1-32)
Dfreq s#,j# supply.d | \
Dbundle s# | \
Djoin -c s# supplier.d - | \
Djoin "" - tmp.d | \
Dselect FIELD j# INCL FIELD j#Jones | Dproj sname,loc
Dfreq with Dbundle produces project number
list for each s#.
Then this list is attached to supplier.d.
The second Djoin with null key field is
cross production.
It appends Jones' project number list (j#Jones)
to all input records.
The condition of Dselect,
FIELD j# INCL FIELD j#Jones"
compares two array fields if the second operand is a subset
of the first operand,
i.e., every element of the second operand is equal to
at least one element of the first operand.
Note that the first keyword
FIELD before j#
may be omitted, while the latter can not be.
13) Find the number of suppliers who supply project #5.
(1-33)
Dselect j# == 5 supply.d | Dfreq s# | Drc | Dproj recordcount
Drc counts the number of records
(, fields and characters as well).
As the Dfreq creates a record for each s#,
number of records is the number of suppliers.
14) Find the part numbers of all parts having the largest quantity-on-hand.
(1-34)
Dmax qoh:n part.d | Dproj p#
Dmax is a filter to select
records with maximum value for the given key field.
15) For each part number being supplied to a project, find as a triple the part number, the project number, and the total quantity of that part being supplied to that project.
(1-35)
Dsort p#:n,j#:n supply.d | \
Dmeans -g p#,j# quantity | Dproj p#,j#,sum.quantity
Dmeans calculates
descriptive statistic values for a given field(s).
Here, it is used calculate total quantity.
The -g p#,j# quantity
(group by) option here
tells Dmeans to calculate total of field
quanitiy for each
p# and j# pair.
For the group by option to work correct,
input file must be sorted by group by fields.
The first step Dsort is just
for this preparation.
Total quantity field is named as
sum.quantity.
This field name is predefined by Dmeans.
If you want other field name, apply
Drename
to the last output file.
16) Find the part number of parts supplied to more than two projects.
(1-36)
Dfreq p#,j# supply.d | \
Dbundle p# | \
Dselect COUNT j# GT 2 | Dproj p#
Dfreq here is, again,
used to extract unique pair of part (p#)
and project (j#).
The field count of Dfreq's output
is not important here.
This step could also be
(1-37)
Dsort p#,j# supply.d | Dproj p#,j# | Dbundle p#,j#
which works as relational projection operation.
Next Dbundle
makes a record per part.
The field j# (and not used count)
becomes repeating field corresponding to the project
to which the part is supplied.
Printing the output from each step will help you to understand.
17) Add DELTA to the quantity-on-hand qoh for the part with part number 3.
Here, we assume DELTA = 75.
In the Codd's original context, DELTA is a variable
of which value is assigned externally.
(1-38)
Ded IF p# == 3 THEN qoh = FIELD qoh + 75 FI part.d
Ded is general purpose
editor for D-files.
It interpretes D-language Dl.
The script is provided as command arguments preceding
the input file name.
As other D-commands, output is written to starndard output.
You have to use redirect (> ouput-file-name)
to save it.
Warning for shell beginers: Never try
Ded ... part.d > part.d.
It will destroy the input file part.d
Explanations may be unnecessary for this program.
Operator == is equality
comparison, while = is
value assignment, like in C language.
FI closes
IF operator, like in sh.
Dl allows some elipses. Full form of this program is
IF FIELD p# == CONST 3 THEN FIELD qoh = FIELD qoh + CONST 75 FI
Using full form may be cumbersome, but it is safe.
For example,
IF p# == 3 THEN qoh = qoh + 75 FI
causes an error.
Because, the second qoh
after = operator is interpreted
as CONST qoh,
and CONST qoh + CONST 75
yields, always, 75.
18) - 21) (These questions are omitted,
because they are specific to the processing model of language "alpha".)
22) Delete the tuple for part number 5 from the data base relation
PART.
(1-39)
Ded IF p# == 5 THEN CURREC = { } FI part.d
Again, Ded is used.
Deletion of a record is done with
CURREC = { }.
This is to assign null to the current record,
and functions as deletion.
There is another way of D-file update,
called Dupdate.
(1-40)
DfromLine p# | Dupdate -d p# part.d -
Terminal will turn into input mode, then input
5 and in the next line
input the EOF character.
This step is to make D-file with just one record
p#:5.
DfromLine is described in
Reading lines section.
Dupdate -d p# reads two D-files:
part.d and the file made by the first step.
It matches key (p#) of both file, and when
it does not match, the record from the first file
is output, when matches, output is detered.
23) - 25) (These questions are omitted, because they are language "alpha"'s processing model specific.)
 Data Processing Utility
Data Processing Utility