![]()
=-= Hypergraph Dualization Repository =-=
Program Codes and Instances for Hypergraph Dualization (minimal hitting set enumeration)
Keisuke Murakami & Takeaki Uno (uno@nii.jp)
![]()
ü@
A hypergraph F is a set family defined on vertex set V such that each set in F (called hyperedge) is a subset of V. For example, the set of {1,2}, {3}, {2,3,4} is a hypergraph. A hitting set H of F is a subset of V such that H intersects any hyperedge of F. A hitting set including no other hitting set is called minimal. For example, {1,3,4} is a hitting set of F, and {1,3} is a minimal hitting set. The dual of a hypergraph F is the set of all minimal hitting sets of F. The problem of computing the dual (also known as minimal hitting set enumeration, minimal set-covering enumeration) is one of a fundamental topic in computer science, and widely studied. For the evaluation of the algorithms and practical benefits, this page provides implementations of the algorithms including that by Takeaki Uno, and many problem instances used in the existing studies. All the instances and implementations are used in our study [1]. We are welcome the submittion of the instances/implementations for the growth of this research field.
contact: Takeaki Uno: uno@nii.ac.jp
ü@
![]() ====
Implementations ====
====
Implementations ====
ü@
![]() SHD (Sparsity-based
Hypergraph Dualization, ver. 3.1) [6] (C code,
Takeaki Uno) Explanation
SHD (Sparsity-based
Hypergraph Dualization, ver. 3.1) [6] (C code,
Takeaki Uno) Explanation
This is an implementation coded by Takeaki Uno. In our experiments, this achieves the fastest for many instances among these implementations. Execution with "0" command is RS algorithm, and with "D" command is DFS algorithm.
![]() BEGK [1] (C code, code by Prof. Khaled Elbassioni, original page)
Note: the code is provided as is, with no warranty, we thank him
for his permitting us to provide his code on our page.
BEGK [1] (C code, code by Prof. Khaled Elbassioni, original page)
Note: the code is provided as is, with no warranty, we thank him
for his permitting us to provide his code on our page.
A quasi polynomial time algorithm. In the sense of time complexity, fastest in this page.
![]() DL [2] (C code, Keisuke Murakami)
DL [2] (C code, Keisuke Murakami)
Breadth first search type algorithm. Add hyperedges one by one with updating the dual.
![]() BMR [3] (C code, Keisuke Murakami)
BMR [3] (C code, Keisuke Murakami)
An improved version of DL algorithm. Add hyperedges in the lexicographic order.
![]() KS [4] (PASCAL, coded by Elias C. Stavropoulos, original page)
KS [4] (PASCAL, coded by Elias C. Stavropoulos, original page)
Depth-first search version of DL algorithm. Needs small memory space. (p2c applied code is included, which needs p2c, and can be compiled with %gcc -o *** ***.c -I/var/tmp/p2c-root/usr/include -lp2c)
![]() MTminer [5] (C code, François Rioult, from this page)
MTminer [5] (C code, François Rioult, from this page)
A hill-climbing type algorithm, i.e., recursively adds vertices in increasing order. Needs much memory.
ü@
![]() ====
Instances ====
====
Instances ====
ü@
![]() ac
(accidents): (all zip) the
complement of the set of maximal frequent itemsets with support threshold t, of dataset
"accidnent" taken from FIMI repository
for frequent itemset mining. A minimal hitting set corresponds to a minimal infrequent
itemset. (a frequent itemset is a vertex subset included in at least t hyperedges, and a
frequent itemset included in no other frequent itemset is called maximal).
"ac_90k" means that the threshold is 90,000.
ac
(accidents): (all zip) the
complement of the set of maximal frequent itemsets with support threshold t, of dataset
"accidnent" taken from FIMI repository
for frequent itemset mining. A minimal hitting set corresponds to a minimal infrequent
itemset. (a frequent itemset is a vertex subset included in at least t hyperedges, and a
frequent itemset included in no other frequent itemset is called maximal).
"ac_90k" means that the threshold is 90,000.
ac 200k ac 150k ac 130k ac 110k ac 90k ac 70k ac 50k ac 30k
![]() bms
(BMS-WebVeiw2): (all zip) the
complement of the set of maximal frequent itemsets with support threshold t, of dataset
"BMS-WebView2" taken from FIMI repository for frequent itemset mining. A minimal
hitting set corresponds to a minimal infrequent itemset. (a frequent itemset is a vertex
subset included in at least t hyperedges, and a frequent itemset included in no other
frequent itemset is called maximal). "bms2_100" means that the threshold is 100.
bms
(BMS-WebVeiw2): (all zip) the
complement of the set of maximal frequent itemsets with support threshold t, of dataset
"BMS-WebView2" taken from FIMI repository for frequent itemset mining. A minimal
hitting set corresponds to a minimal infrequent itemset. (a frequent itemset is a vertex
subset included in at least t hyperedges, and a frequent itemset included in no other
frequent itemset is called maximal). "bms2_100" means that the threshold is 100.
bms2 800 bms2 400 bms2 200 bms2 100 bms2 50 bms2 30 bms2 20 bms2 10
![]() connect-4
(win): (all zip) the set of
minimal winning borad of a board game "connect-4". The files are the first k
hyperedges. This data is taken from UCI
machine learning repository. "w200" means it containes the first
200 hyperedges.
connect-4
(win): (all zip) the set of
minimal winning borad of a board game "connect-4". The files are the first k
hyperedges. This data is taken from UCI
machine learning repository. "w200" means it containes the first
200 hyperedges.
win100 win200 win400 win800 win1600 win3200 win6400 win12800 win25600 win (all)
![]() connect-4
(lose): (all zip) the set
of minimal winning borad of a board game "connect-4". The files are the first k
hyperedges. This data is taken from UCI
machine learning repository. "l200" means it containes the first
200 hyperedges.
connect-4
(lose): (all zip) the set
of minimal winning borad of a board game "connect-4". The files are the first k
hyperedges. This data is taken from UCI
machine learning repository. "l200" means it containes the first
200 hyperedges.
lose100 lose200 lose400 lose800 lose1600 lose3200 lose6400 lose12800 lose (all)
![]() matching:
(all zip) matching of size k/2
(so, k vertices); the file is composed of hyperedges {1,2}, {3,4}, {5,6},...
matching:
(all zip) matching of size k/2
(so, k vertices); the file is composed of hyperedges {1,2}, {3,4}, {5,6},...
matching20 matching24 matching28 matching30 matching32 matching34 matching36 matching38 matching40 matching42 matching44 matching46
![]() dual-matching:
(all zip) dual of the
matching of size k/2.
dual-matching:
(all zip) dual of the
matching of size k/2.
dual-matching20 dual-matching24 dual-matching28 dual-matching30 dual-matching32 dual-matching34 dual-matching36 dual-matching38 dual-matching40 dual-matching42 dual-matching44 dual-matching46
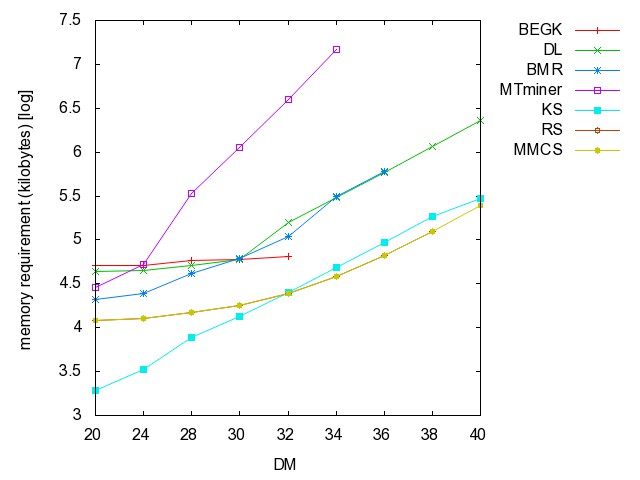
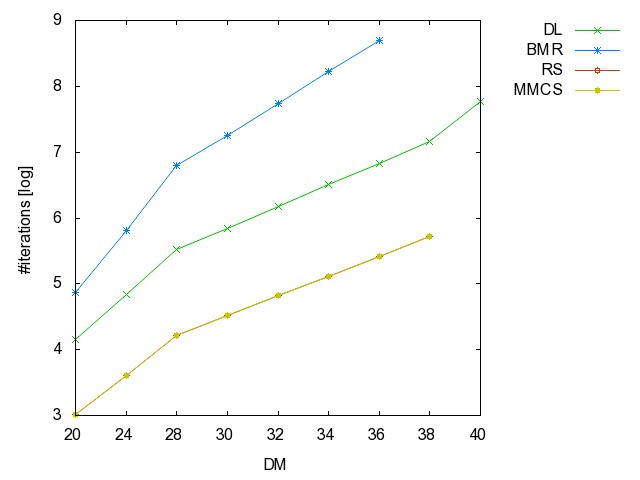
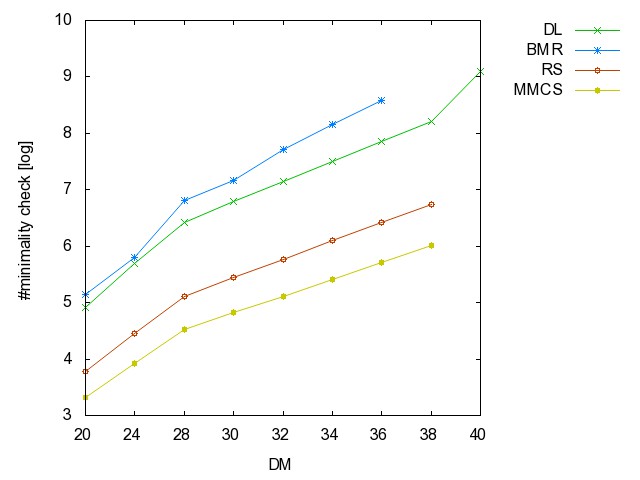
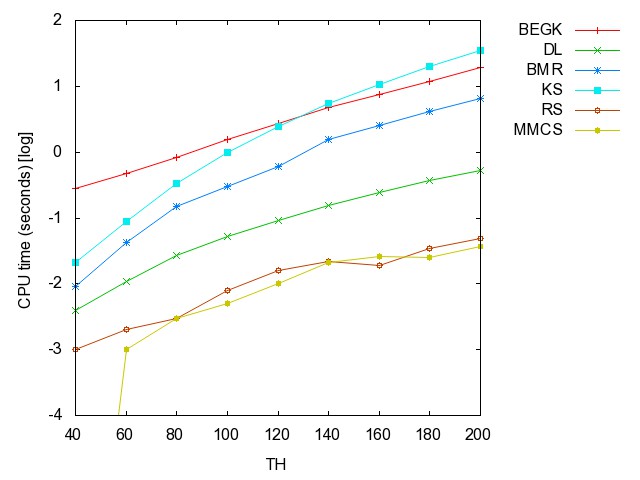
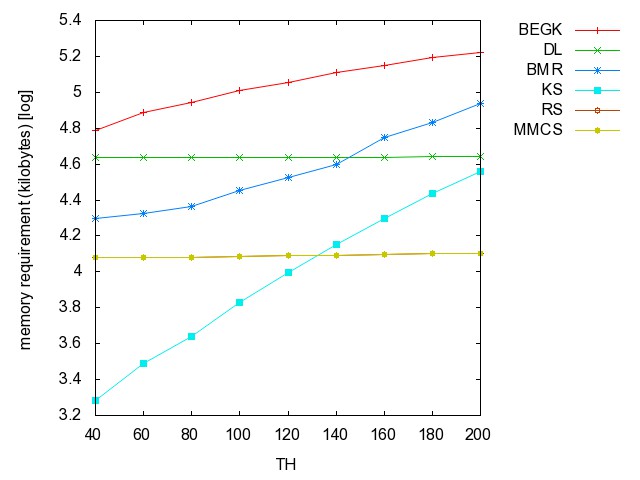
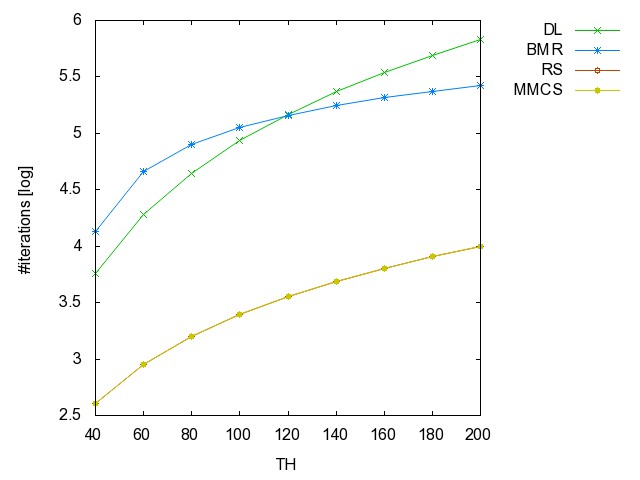
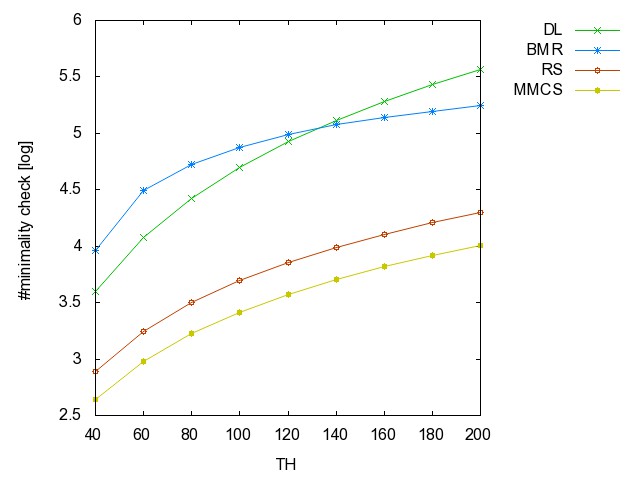
![]() Threshold
graph (TH): (all zip) the hyperedge
set of this series of hypergraphs is { {i,j} | {1 <= i, j <= n,
j is even }.
Threshold
graph (TH): (all zip) the hyperedge
set of this series of hypergraphs is { {i,j} | {1 <= i, j <= n,
j is even }.
TH40 TH60 TH80 TH100 TH120 TH140 TH160 TH180 TH200
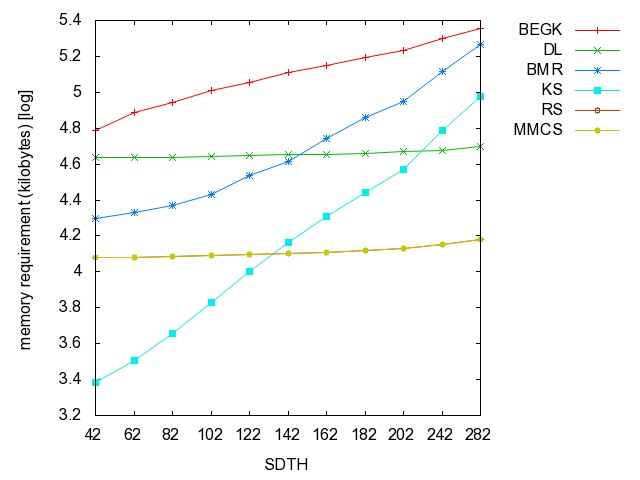
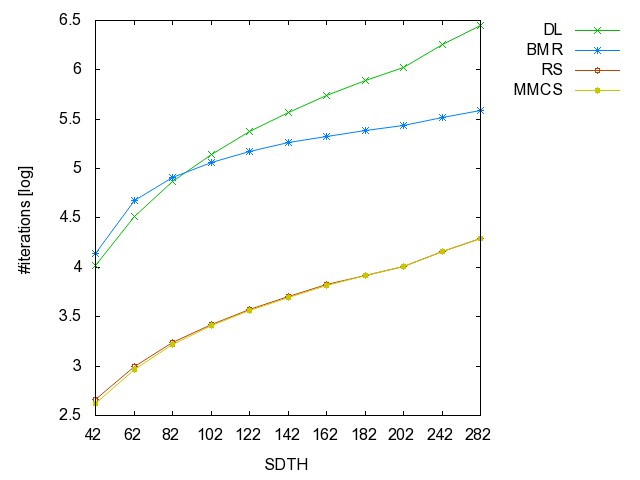
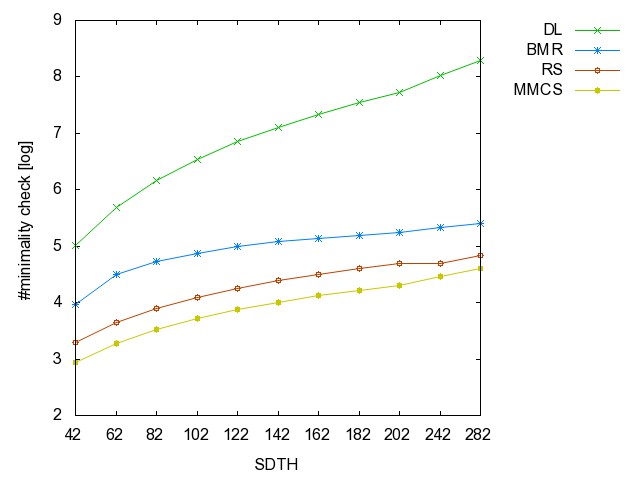
![]() Self-Dual
Threshold graph (SDTH): (all zip)
the hyperedge set of these graphs are {n,n-1}, each hyperedge of TH(n-2)
+ {n}, each hyperedge of TH(n-2) +
{n-1}.
Self-Dual
Threshold graph (SDTH): (all zip)
the hyperedge set of these graphs are {n,n-1}, each hyperedge of TH(n-2)
+ {n}, each hyperedge of TH(n-2) +
{n-1}.
SDTH42 SDTH62 SDTH82 SDTH102 SDTH122 SDTH142 SDTH162 SDTH182 SDTH202 SDTH242 SDTH282 SDTH322 SDTH362 SDTH402
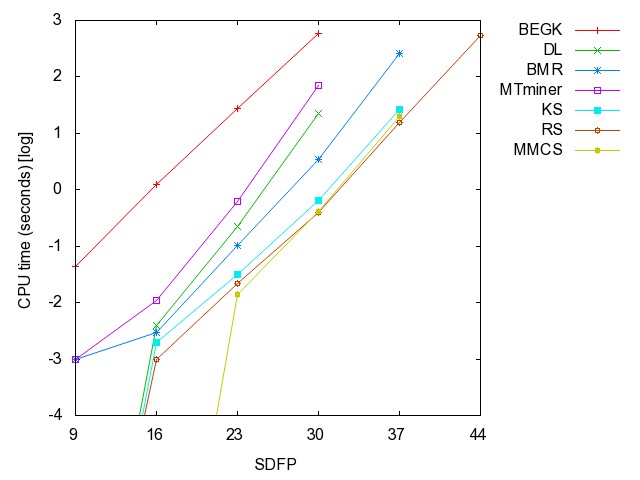
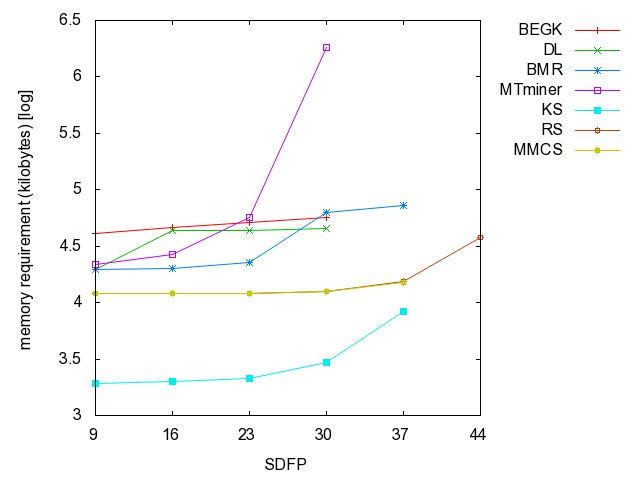
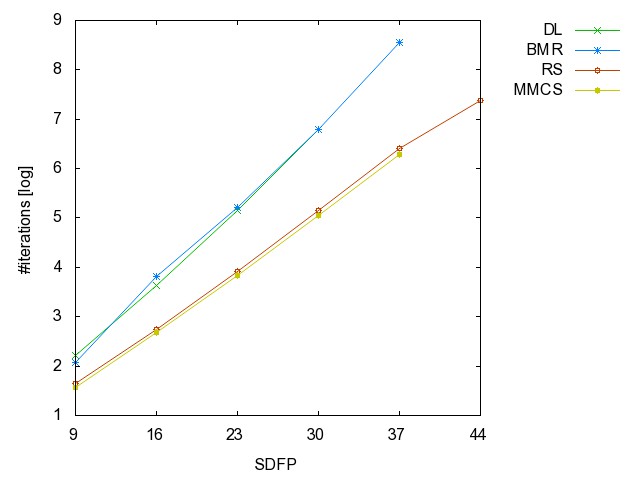
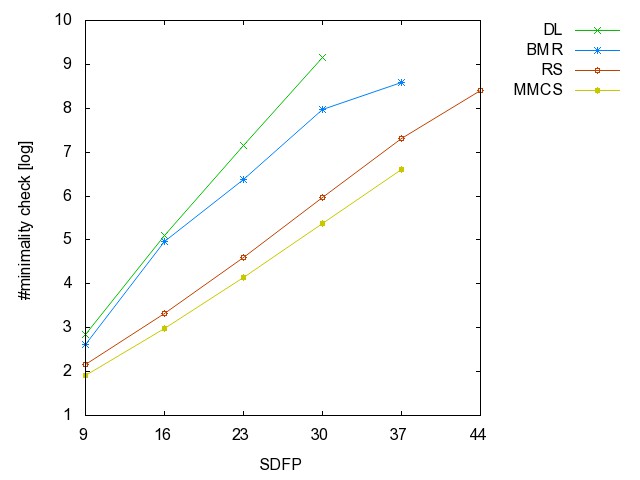
![]() Self-Dual
Fano Plane graph (SDFP): (all zip) the
hyperedges are the union of k-disjoint copies of {{1,2,3},{1,5,6},{1,7,4},{2,4,5},{2,6,7},{3,4,6},{3,5,7}}.
Self-Dual
Fano Plane graph (SDFP): (all zip) the
hyperedges are the union of k-disjoint copies of {{1,2,3},{1,5,6},{1,7,4},{2,4,5},{2,6,7},{3,4,6},{3,5,7}}.
SDFP9 SDFP16 SDFP23 SDFP30 SDFP37 SDFP44 SDFP51
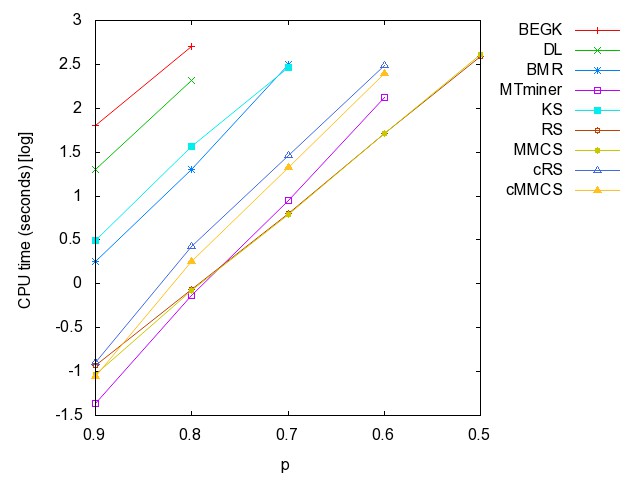
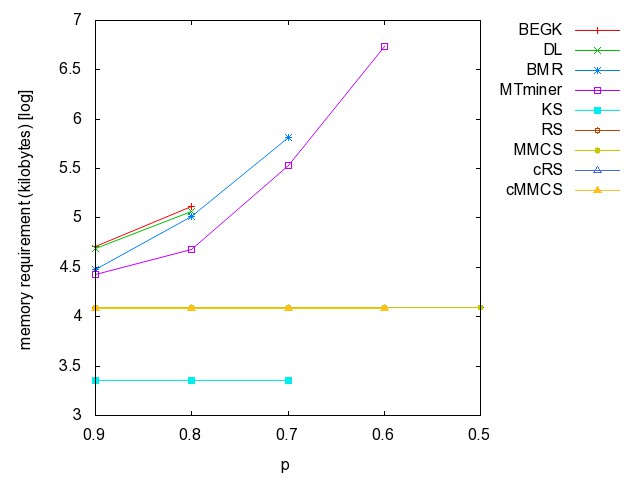
![]() uniform
random: (all zip) random
instances; each vertex is included in a hyperedge in the probability p.
(generated by Prof. Alain Bretto)
uniform
random: (all zip) random
instances; each vertex is included in a hyperedge in the probability p.
(generated by Prof. Alain Bretto)
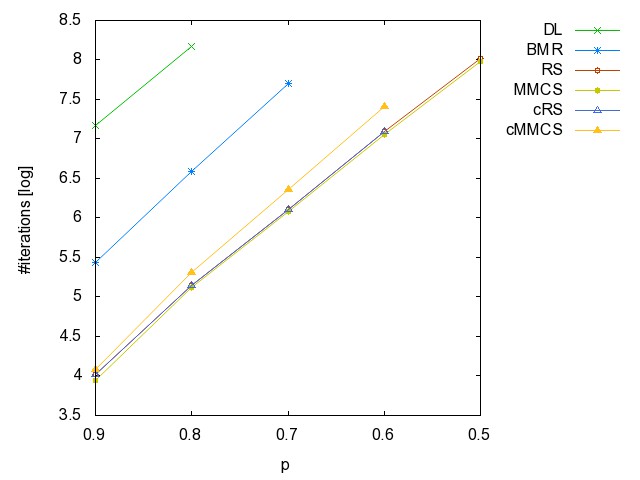
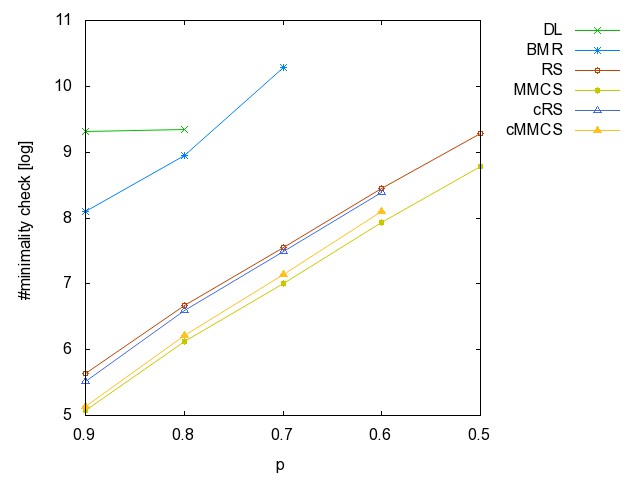
prob=0.99, 1000 prob=0.99, 2000 prob=0.99, 4000 prob=0.99, 8000 prob=0.99, 16000 prob=0.99, 32000 prob=0.99, 64000 prob=0.99, 128000 prob=0.99, 256000 prob=0.99, 512000 prob=0.99, 1024000
prob=0.98, 1000 prob=0.98, 2000 prob=0.98, 4000 prob=0.98, 8000 prob=0.98, 16000 prob=0.98, 32000 prob=0.98, 64000 prob=0.98, 128000 prob=0.98, 256000 prob=0.98, 512000 prob=0.98, 1024000
prob=0.95, 1000 prob=0.95, 2000 prob=0.95, 4000 prob=0.95, 8000 prob=0.95, 16000 prob=0.95, 32000 prob=0.95, 64000 prob=0.95, 128000 prob=0.95, 256000 prob=0.95, 512000 prob=0.95, 1024000
prob=0.9, 1000 prob=0.9, 2000 prob=0.9, 4000 prob=0.9, 8000 prob=0.9, 16000 prob=0.9, 32000 prob=0.9, 64000 prob=0.9, 128000 prob=0.9, 256000 prob=0.9, 512000 prob=0.9, 1024000
prob=0.8, 1000 prob=0.8, 2000 prob=0.8, 4000 prob=0.8, 8000 prob=0.8, 16000 prob=0.8, 32000 prob=0.8, 64000 prob=0.8, 128000 prob=0.8, 256000 prob=0.8, 512000 prob=0.8, 1024000
prob=0.7, 1000 prob=0.7, 2000 prob=0.7, 4000 prob=0.7, 8000 prob=0.7, 16000 prob=0.7, 32000 prob=0.7, 64000 prob=0.7, 128000 prob=0.7, 256000 prob=0.7, 512000 prob=0.7, 1024000
prob=0.6, 1000 prob=0.6, 2000 prob=0.6, 4000 prob=0.6, 8000 prob=0.6, 16000 prob=0.6, 32000 prob=0.6, 64000 prob=0.6, 128000 prob=0.6, 256000 prob=0.6, 512000 prob=0.6, 1024000
prob=0.5, 1000 prob=0.5, 2000 prob=0.5, 4000 prob=0.5, 8000 prob=0.5, 16000 prob=0.5, 32000 prob=0.5, 64000 prob=0.5, 128000 prob=0.5, 256000 prob=0.5, 512000 prob=0.5, 1024000
prob=0.4, 1000 prob=0.4, 2000 prob=0.4, 4000 prob=0.4, 8000 prob=0.4, 16000 prob=0.4, 32000 prob=0.4, 64000 prob=0.4, 128000 prob=0.4, 256000 prob=0.4, 512000 prob=0.4, 1024000
prob=0.3, 1000 prob=0.2, 1000 prob=0.1, 1000 prob=0.8, 200 prob=0.8, 600 prob=0.8, 10000 prob=0.8, 20000
ü@
![]() ====
Experiments ====
====
Experiments ====
ü@
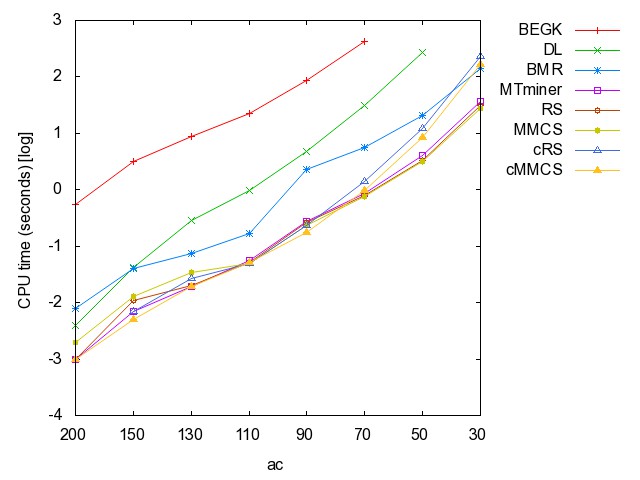
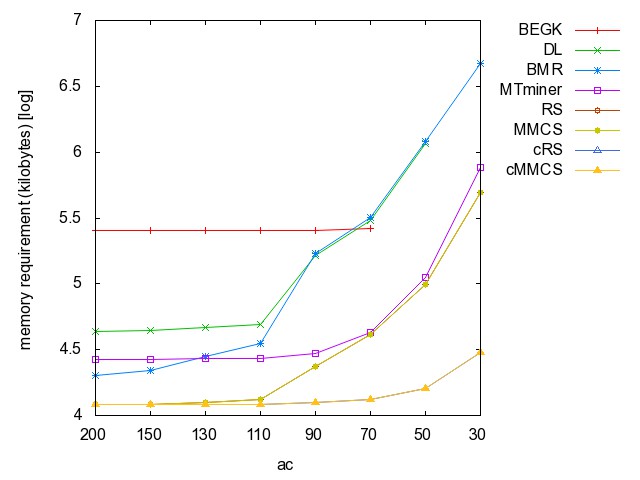
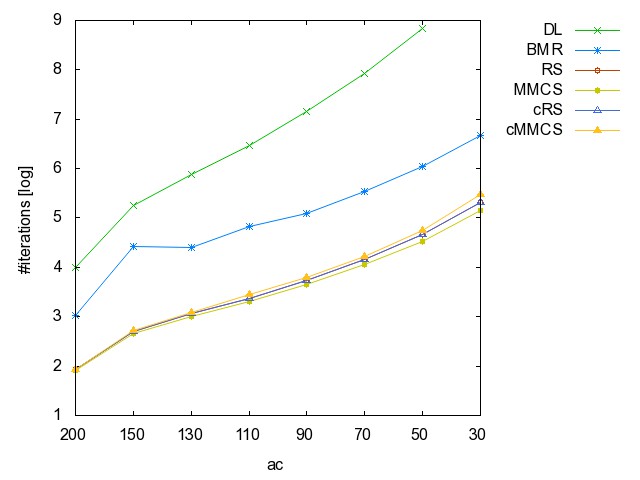
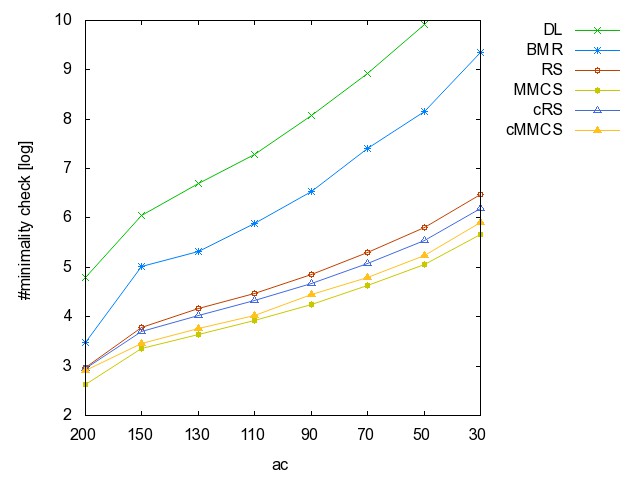
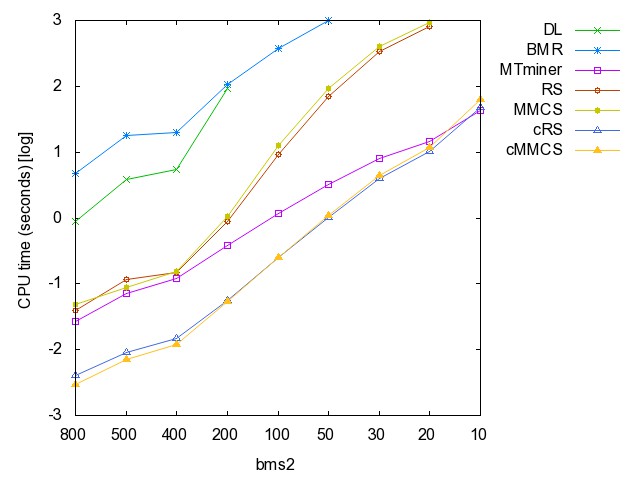
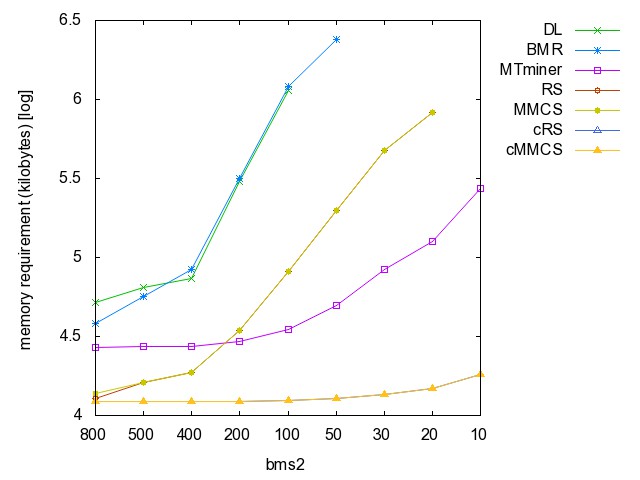
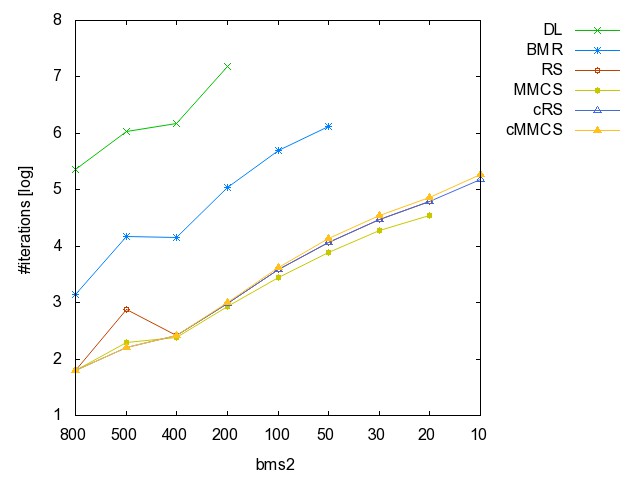
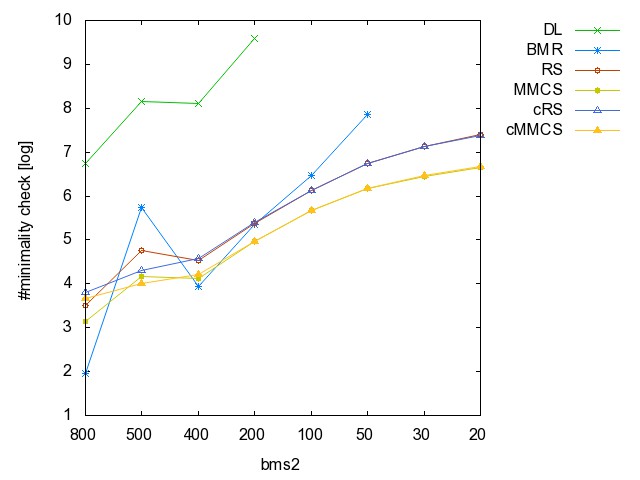
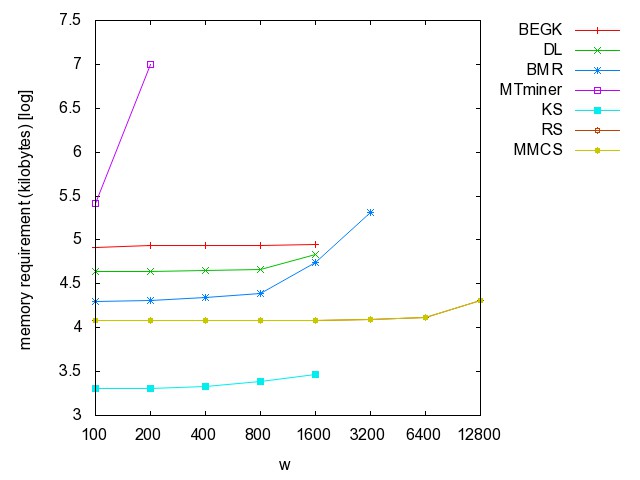
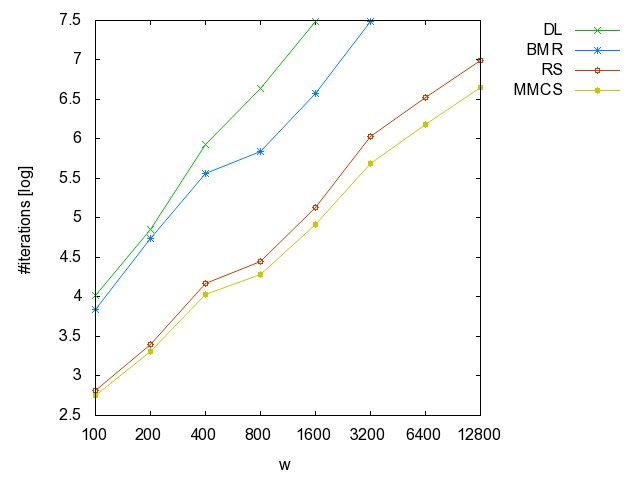
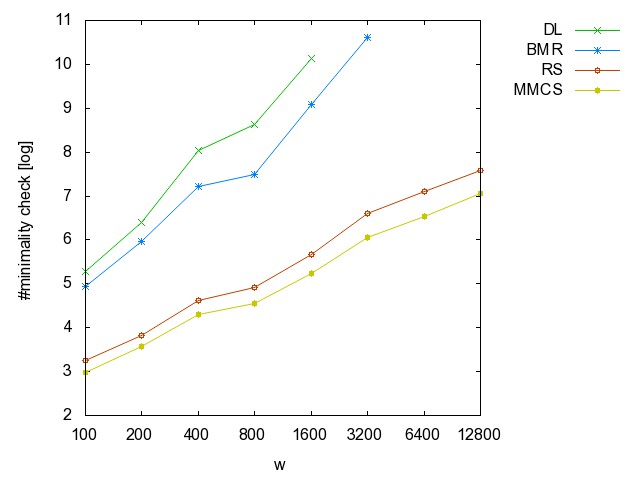
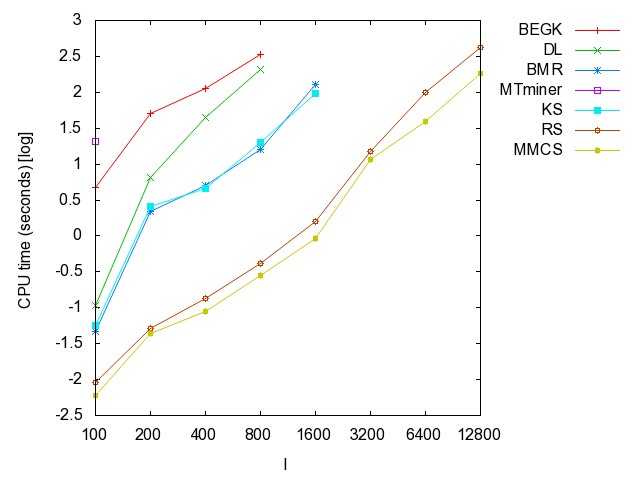
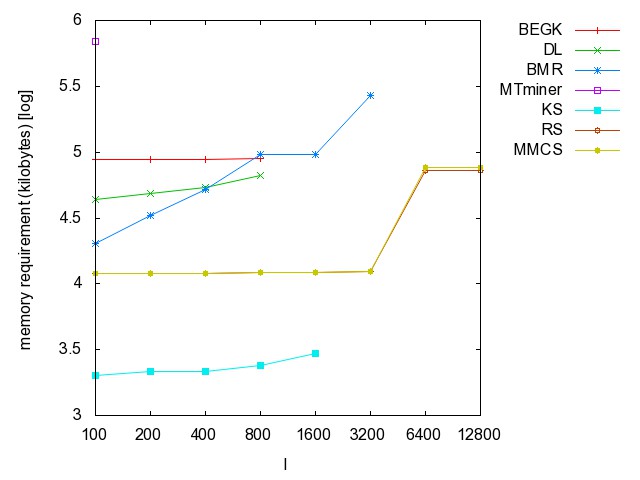
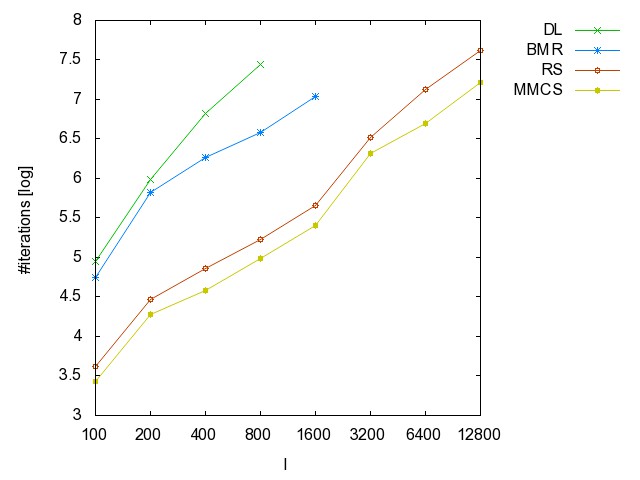
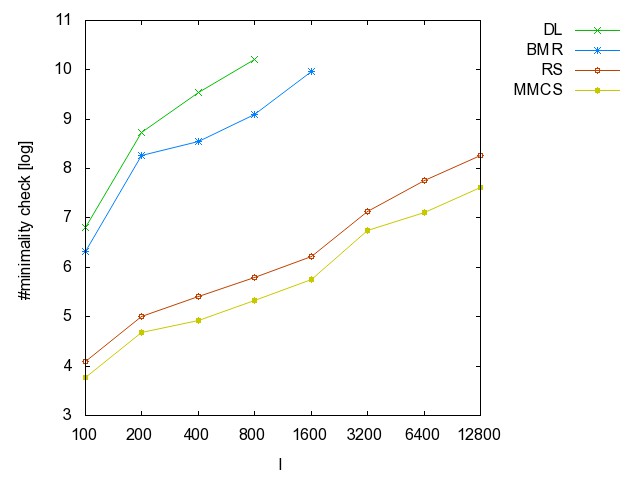
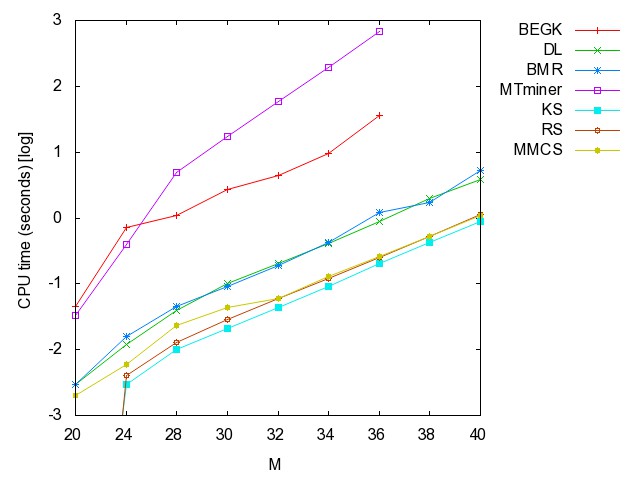
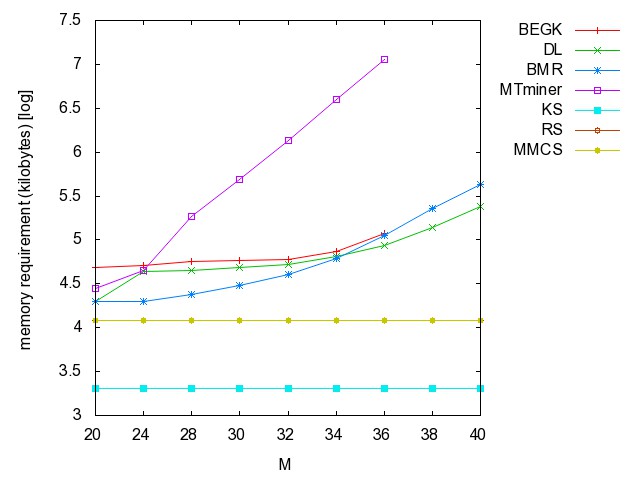
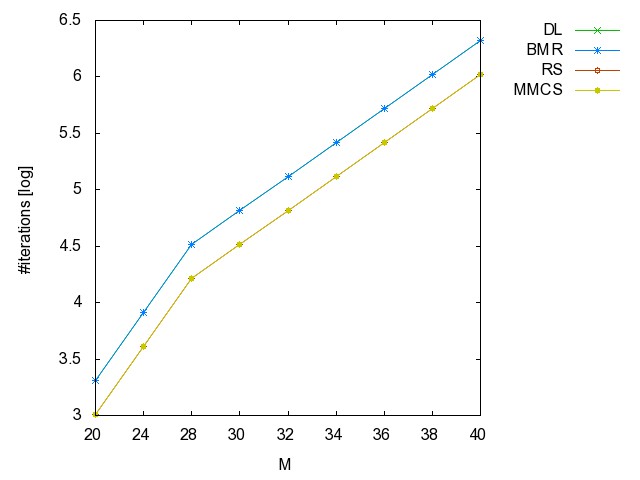
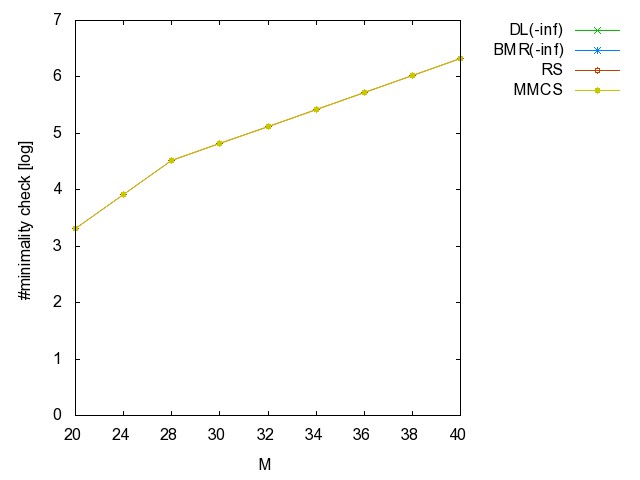
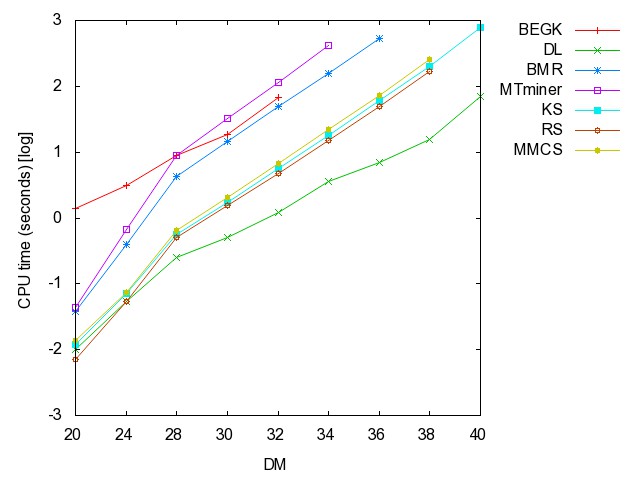
![]() ac
(accidents): time [csv]
memory [csv]
#iterations [csv]
#minimality
checks [csv]
ac
(accidents): time [csv]
memory [csv]
#iterations [csv]
#minimality
checks [csv]
![]() bms
(BMS-WebVeiw2): time [csv]
memory [csv]
#iterations [csv]
#minimality
checks [csv]
bms
(BMS-WebVeiw2): time [csv]
memory [csv]
#iterations [csv]
#minimality
checks [csv]
![]() connect-4
(win): time [csv]
memory [csv]
#iterations [csv]
#minimality
checks [csv]
connect-4
(win): time [csv]
memory [csv]
#iterations [csv]
#minimality
checks [csv]
![]() connect-4
(lose): time [csv]
memory [csv]
#iterations [csv]
#minimality
checks [csv]
connect-4
(lose): time [csv]
memory [csv]
#iterations [csv]
#minimality
checks [csv]
![]() matching:
time [csv]
memory [csv]
#iterations [csv]
#minimality checks [csv]
matching:
time [csv]
memory [csv]
#iterations [csv]
#minimality checks [csv]
![]() dual-matching:
time [csv]
memory [csv]
#iterations [csv]
#minimality checks [csv]
dual-matching:
time [csv]
memory [csv]
#iterations [csv]
#minimality checks [csv]
![]() Threshold
graph: time [csv]
memory [csv]
#iterations [csv]
#minimality
checks [csv]
Threshold
graph: time [csv]
memory [csv]
#iterations [csv]
#minimality
checks [csv]
![]() Self-Dual
Threahold graph: time [csv]
memory [csv]
#iterations [csv]
#minimality
checks [csv]
Self-Dual
Threahold graph: time [csv]
memory [csv]
#iterations [csv]
#minimality
checks [csv]
![]() Self-Dual
Fano Plane graph: time [csv]
memory [csv]
#iterations [csv]
#minimality
checks [csv]
Self-Dual
Fano Plane graph: time [csv]
memory [csv]
#iterations [csv]
#minimality
checks [csv]
![]() uniform
random: time [csv]
memory [csv]
#iterations [csv]
#minimality
checks [csv]
uniform
random: time [csv]
memory [csv]
#iterations [csv]
#minimality
checks [csv]
ü@
----------------------------------
[1] Leonid Khachiyan, Endre Boros, Khaled M. Elbassioni, Vladimir Gurvich, "An Efficient Implementation of a Quasi-polynomial Algorithm for Generating Hypergraph Transversals and its Application in Joint Generation", Discrete Applied Mathematics 154(16): 2350-2372 (2006)
[2] G. Dong and J. Li, "Mining Border Descriptions of Emerging Patterns from Dataset Pairs", Knowledge and Information Systems 8: 178-202 (2005).
[3] J. Bailey, T. Manoukian, and K. Ramamohanarao, "A Fast Algorithm for Computing Hypergraph Transversals and its Application in Mining Emerging Patterns", 3rd IEEE International Conference on Data Mining (ICDM 2003):485-488 (2003).
[4] D. J. Kavvadias and E. C. Stavropoulos, "An Efficient Algorithm for the Transversal Hypergraph Generation", Journal of Graph Algorithms and Applications 9: 239-264 (2005).
[5] C. He'bert, A. Bretto and B. Cre'milleux, "A Data Mining Formalization to Improve Hypergraph Minimal Transversal Computation", Fundamental Informaticae 80:415-433 (2007).
[6] Keisuke Murakami, Takeaki Uno, "Efficient Algorithms for Dualizing Large Scale Hypergraphs",
ü@
![]()
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}