タスクの説明: 第2回NTCIR Workshop
| 第2回NTCIRworkshopは 終了しました |
| 最新のNTCIRworkshopは |
| 第2回NTCIRworkshopは 終了しました |
| 最新のNTCIRworkshopは |
 中国語検索タスク(Chinese IR task): 中国語の単言語検索、英語・中国語の言語横断検索。中国語の文書群に対 して、新しい英語または中国語の検索課題で検索を行い、その検索有効性
を調べる。 中国語検索タスクの詳細はこちら http://lips.lis.ntu.edu.tw/cirb/events-1.htm 関連情報も同じWebサイトにあります。 http://lips.lis.ntu.edu.tw/cirb/index.htm 中国語のみの情報もあります。
日本語・英語検索タスク (Japanese & English IR task): 日本語または英語の単言語検索、英語・日本語の言語横断検索。言語横断検
索では日本語または英語だけの文書群、もしくは日本語と英語の混ざった文 書群を、日本語または英語の検索課題で検索し、その検索有効性を調べる。
自動要約タスク (text summarization task): 日本語文書の要約
中国語検索タスク(Chinese IR task): 中国語の単言語検索、英語・中国語の言語横断検索。中国語の文書群に対 して、新しい英語または中国語の検索課題で検索を行い、その検索有効性
を調べる。 中国語検索タスクの詳細はこちら http://lips.lis.ntu.edu.tw/cirb/events-1.htm 関連情報も同じWebサイトにあります。 http://lips.lis.ntu.edu.tw/cirb/index.htm 中国語のみの情報もあります。
日本語・英語検索タスク (Japanese & English IR task): 日本語または英語の単言語検索、英語・日本語の言語横断検索。言語横断検
索では日本語または英語だけの文書群、もしくは日本語と英語の混ざった文 書群を、日本語または英語の検索課題で検索し、その検索有効性を調べる。
自動要約タスク (text summarization task): 日本語文書の要約
 検索系サブタスクは、 「検索課題の言語(C,J,E) - 文書の言語(C,J,E)」 で示します(Cは中国語、Jは日本語、Eは英語)
検索系サブタスクは、 「検索課題の言語(C,J,E) - 文書の言語(C,J,E)」 で示します(Cは中国語、Jは日本語、Eは英語)
 中国語検索タスク(Chinese IR task) 中国語の単言語検索、英語・中国語の言語横断検索。中国語の文書群に対 して、新しい英語または中国語の検索課題で検索を行い、その検索有効性
を調べる。
中国語検索タスク(Chinese IR task) 中国語の単言語検索、英語・中国語の言語横断検索。中国語の文書群に対 して、新しい英語または中国語の検索課題で検索を行い、その検索有効性
を調べる。 (1) タスクの説明
The Chinese Text Retrieval Tasks focus on the evaluation of an IR system
in retrieving Chinese texts based on topics in either Chinese or English.
The training set and the testing set of Chinese Text Retrieval Tasks are
selected from the Chinese Information Retrieval Benchmark 1 (CIRB-1). The
CIRB-1 consists of three parts: 1) Document Set; 2) Topic Set; and 3) Relevance
Judgment. Now, the Document Set contains 132,173 news articles from 5 news
agencies in Taiwan, the Topic Set contains 50 topics in a form of user's
information need from briefs to details, and the Relevance Judgment consists
of the related documents to the various topics.
 Chinese IR Task (The Monolingual IR (C-C Task))
English-Chinese IR Task (The Cross-Lingual IR (E-C Task))
As soon as possible: Submit an application.
August 31, 2000: CIRB-1-CH CD (132,172 documents and 50 Chinese topics) will be distributed
to the participants of Chinese IR Task, and CIRB-1-EN CD (132,172 documents
and 50 English topics) will be distributed to the participants of English-Chinese
IR Task.
October 20, 2000: Search results and system description forms submission.
January 10, 2001: Results of Relevance Assessments will be distributed to the participants.
February 12, 2001: Papers for the working-note proceedings submission.
March 7-9, 2001: Workshop meeting at NII, Tokyo, Japan.
March 16, 2001: Camera-ready copies for the proceedings.
日本語・英語検索タスク (Japanese & English IR task):日本語または英語の単言語検索、英語・日本語の言語横断検索。 特定のデータベースに対して、新しい検索課題の検索を行い、その検索有効性を調べる。
対話型システムも参加できます。
Chinese IR Task (The Monolingual IR (C-C Task))
English-Chinese IR Task (The Cross-Lingual IR (E-C Task))
As soon as possible: Submit an application.
August 31, 2000: CIRB-1-CH CD (132,172 documents and 50 Chinese topics) will be distributed
to the participants of Chinese IR Task, and CIRB-1-EN CD (132,172 documents
and 50 English topics) will be distributed to the participants of English-Chinese
IR Task.
October 20, 2000: Search results and system description forms submission.
January 10, 2001: Results of Relevance Assessments will be distributed to the participants.
February 12, 2001: Papers for the working-note proceedings submission.
March 7-9, 2001: Workshop meeting at NII, Tokyo, Japan.
March 16, 2001: Camera-ready copies for the proceedings.
日本語・英語検索タスク (Japanese & English IR task):日本語または英語の単言語検索、英語・日本語の言語横断検索。 特定のデータベースに対して、新しい検索課題の検索を行い、その検索有効性を調べる。
対話型システムも参加できます。 (1) タスクの説明
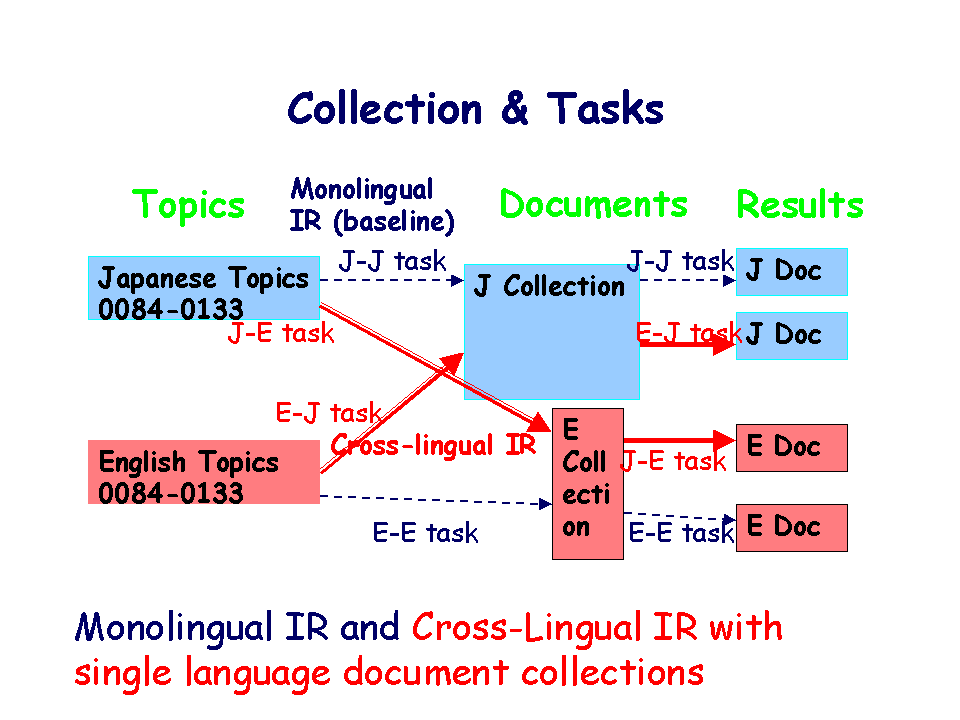
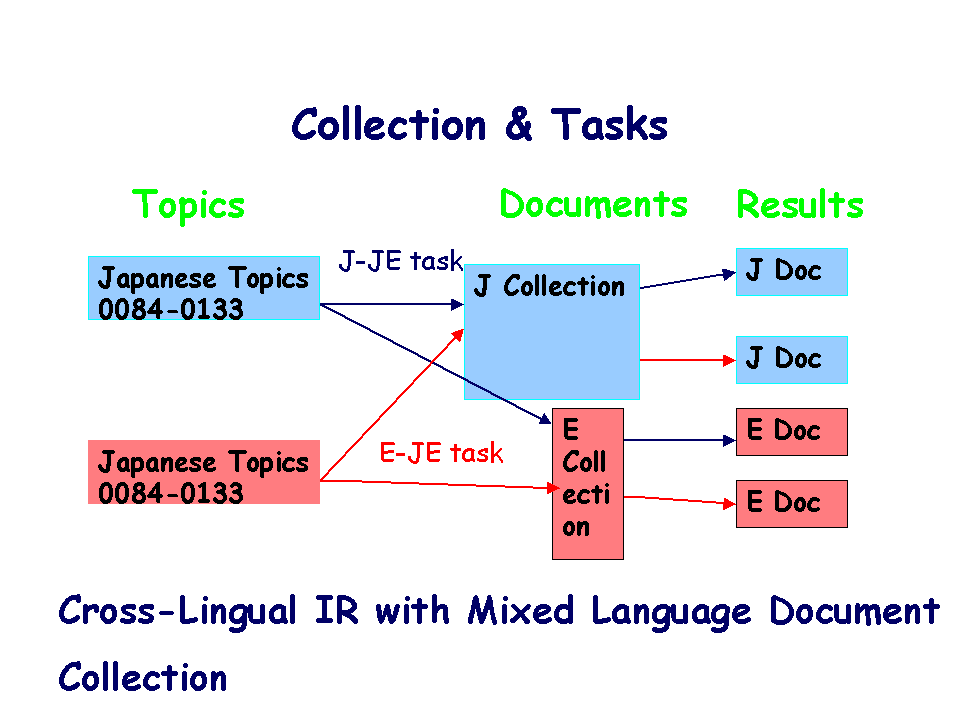
次の二つのサブカテゴリがあります。(1) 単言語検索 (Monolingual IR), (2)
言語横断検索 (Cross-Lingual IR)
単言語検索は、
言語横断検索は、
各タスクと検索課題、文書コレクションの関係は、以下の通りです。
  |
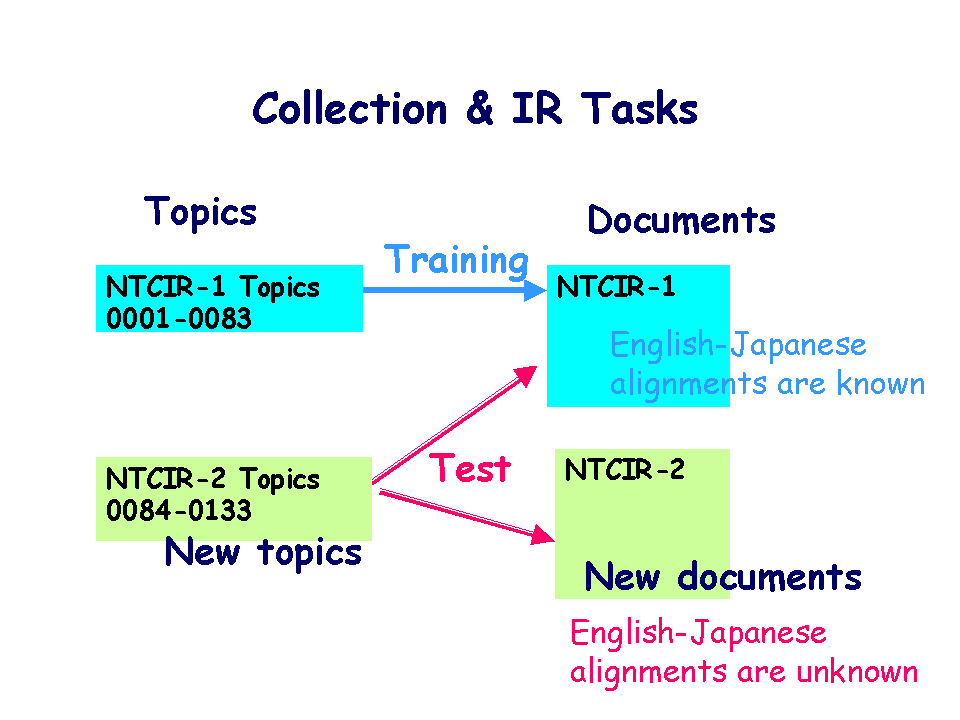
「テストコレクション1(NTCIR-1)」を 訓練(training)用データセットとして使用します。
NTCIR-1には、約33万件の文書、83個の検索課題、その正解文書リストが 含まれます。文書の半数以上は、日英の対訳(文書レベルの対応)です。
日本語と英語の対応する文書は、文書ID(ACCN)が同一で、 対応付けが明らかです。この日英の対応も訓練、辞書や知識ベー
スの作成に使用することができます。
「テストコレクション2(NTCIR-2)(予備版)」のCDを8月に配布します。 NTCIR-2には、新しい文書約40万件と新しい検索課題50件が含まれ ます。 評価(test)では、NTCIR-1とNTCIR-2の文書に対して、新しい NTCIR-2の検索課題50件で検索を行った結果の検索有効性を調べます。 この検索結果(各課題ごとに、上位1000件)を事務局に提出してください。 提出用フォーマットはサンプルHOMEにあります。
訓練用(training)データと評価用(test)データの関係は、以下の 通りです。
 |
検索課題(topics)は、利用者の 検索要求を一定の書式で記述したものです。 検索式は、この検索課題から自動的に作成しても、手作業で作
成してもかまいません。 検索式を自動構築する場合は、検索課題の中の<DESCRIPTION>のみを用
いた検索が必須です。これはシステム間の比較を行いやすくするためです。 検索式を自動構築する場合でも、2つめ以降の実行結果では、検索
課題のどの部分を用いて検索を行っても構いません。 対話型検索システムなど、検索式の構築になんらかの形で人手が介在する
場合は、検索課題のどの部分を用いても構いません。いずれの場合も、 検索結果提出時に、検索課題中で使用した項目を報告します。
検索結果は、1チームで複数を提出することが可能です。複数提出す る場合は、優先順位を付けてください。
事務局では、集まった検索結果について正解判定を行ない、正解文書 リストを作成し、全参加者に配布します。また、評価プログラムによ って、精度・再現率などの評価尺度を算出した結果を各参加者にお知 らせします。分析の助けになるように、検索課題ごとにみた全提出結 果の間での各評価値のメディアンなども同時にお知らせいたします。 また、これらの結果は、会議録にもチームIDとともに、付録として収 録されます。 評価プログラムは、テストコレクション・プロジェクトのサイトおよ びコーネル大学のftpサイトから入手可能です
訓練用データ
訓練には、「NACSISテストコレクション1(NTCIR-1)」 CD-ROMの 「Jコレクション(mlir/ntc1-j1.tgz)」と 「Eコレクション(clir/ntc1-e1.tgz)」 が使用できます。「JEコレクション(adhoc/ntc1-je1.tgz)」に相当する 文書コレクションは、評価では使用しませんので、ご注意下さい。 正解文書リストは、それぞれ、 「Jコレクション(mlir/ntc1-j1.tgz)」と「Eコレクション(clir/ntc1-e1.tgz)」 の中にあるものをお使いください。
NTCIR-1の文書は、「学会発表データベース」から抽出したレコードの 一部であり、日本国内の65の学会で発表された論文の著者抄録です。 半数以上は、その論文の著者が日本語と英語の対訳(文書レベルの対応) の文書として作成したものです。その中から、日本語部分だけをとりだ したものが、「Jコレクション」、英語部分だけをとりだしたものが、 「Eコレクション」です。 「Eコレクション」の多くの文書は、「Jコレクション」の中に、対応す るレコードがありますが、すべて対応するものがあるという訳では ありません。また、対訳になっている文書同士であっても、細かい点で 記述の仕方が異なるため、正解判定が異なっている場合が、少数ですがあります。
NTCIR-1では、「Jコレクション」と、「Eコレクション」で、対応するレコード同士は、 同じACCN(文書ID)を持っています。この対応付けは、システムの訓練、 言語横断検索用の辞書や知識ベースの構築に使用できます。
ご注意ください! NTCIR-2と形式をそろえるために、 NTCIR-1のACCNを、以下のように変更していただく必要があります。
評価用データ
NTCIR-1の中の「Jコレクション」と「Eコレクション」ならびにNTCIR-2を使用します。 新たに配布するNTCIR-2(予備版)にも、日本語文書のみからなる「Jコレクション」 と英語文書のみからなる「Eコレクション」があります。 検索課題は、日本語と英語があります。 NTCIR-2の文書には、2つのサブファイルがあります。(1)科学研究費補助金 報告書の要旨(約30万件)と(2)学会発表論文の著者抄録(約10万件)。(1)の約25%、 (2)の約半数は、日英対訳(文書レベルの対応)ですが、対応づけは、結果提出まで お知らせしません。 (1) の平均文書長は、NTCIR-1の文書のおよそ3倍程度です。(文書長別の文書数 の分布は、 http://research.nii.ac.jp/ntcir/workshop/length-en.html でご覧になれます)
語分割データ
NTCIR-1とNTCIR-2中の日本語文書と日本語検索課題について は、あらかじめ、語と語構成要素に分割したテキストも用意します。海外からの 参加者への支援として、また、より詳細なシステム間の比較を可能にするために 用意いたしました。必須ではありませんが、語分割アルゴリズム間の比較の基準 データ、検索アルゴリズムを比較する際のテキスト分割のデフォルトなどとして、 活用してください。
語分割データでは、語と語構成要素の2つのレベルに分割されています。索引語には、
データの詳しい説明とサンプルは、 データHomeと サンプルHome をご参照ください。
の尺度について、各検索課題ごとの値と全検索課題の平均を算出します。 言語横断検索については、単言語検索の何パーセントの有効性を達成したか も調べます。また、これらの評価結果は、各参加者にお返しします。
このワークショップの主な目的は、これらの 評価尺度によって参加したシステムを順位づけることではなく、 多様な検索手法やアプローチ の相互の比較、どの手法がどのような効果をもたらすかなど について、相互に議論、意見交換などを行う場を提供することによって、 日本語情報検索の研究を促進すること、さらには、参加者の方からのフィ ードバックにもとづいて、テストコレクションを改善することです。 積極的に多様なアプローチが提案されることを期待しています。 また、参加者用のメーリングリストと成果報告会において、活発な議論 がもたれることも期待しています。議論や意見交換などのために、 成果報告会とは別に会合を持ちたいというご要望があれば、いつでも、 議論の場を用意したいと思います。ワークショップの運営、日程、タスクなど についてもご意見、ご提案も、歓迎いたします。
たとえば、今回のワークショップでは、以下ような点などについて、理解が進むことを期 待しています。以下は観点の例であって、これだけに限定するものではありません。自由 な発想で多くの研究が生まれることを期待しています。
(i) 日本語テキストに適した検索アルゴリズムとパラメータ
昨年のNTCIR Workshop 1では、時間的な制約のため、多くの参加グループが、 英語テキストの検索では有効性が示されているアルゴリズムとパラメータを そのまま日本語に適応していました。インタネット上の文書で英語の次に多いのは 日本語だという統計もあり、「英語にも日本語にも有効なアルゴリズム」だけでなく、 「日本語により適したアルゴリズムやパラメータは何か?」ということ にも国内外から関心が集まっています。多くのチャレンジを期待しています。
(ii) 日本語テキストの分割法と検索アルゴリズムの関係
日本語文書の検索については、それぞれのシステムがそれぞれのテキスト分割法と それぞれの検索アルゴリズムを用いており、要素技術の検索有効性への効果を検討 する際、システム間の比較が複雑で、わかりにくくなっています。 また、語・単語型索引は、使用する語彙的資源の規模や種類の影響を受ける可能性 があると考えられますが、 海外からの参加者は使用できる語彙的資源が必ずしも充分でない場合が少なくあり ません。そこで、今回のNTCIR Workshopでは、日本語の文書と検索課題について、 ひとつの語分割の基準データも用意しました。
語分割データ導入の意図は、(1)海外からの参加者への支援、とともに、(2)分割法の検索 有効性への効果、及び(3)分割法による影響を少なくした場での検索アルゴリズムの検索 有効性への効果の検討の促進です。語分割データの利用は必須ではありませんが、可能な らば、(そして関心があれば)、テキスト分割法について検討する場合は、各チームの独自 の分割法とともに、この語分割データを同じ検索アルゴリズムで試していただければ幸い です。また、検索アルゴリズムを検討する場合は、システム間の比較を促進するために、 可能ならば、この語分割データも使用してみてください。
語分割データの問題点としては、(1)対象データに合わせた分割法のチューニングの効果に ついて検討できない、アルゴリズムと分割法の相乗効果について検討できない、(3)pat trieなどのように語分割に関わらない索引構造について検討できないなど、多くの点があ げられます。 このような問題の影響を検討し、その影響を排除するための手がかりとして、システム に最終的に投入された問い合わせの語のリストを利用したいと考えております。そ こで、皆様にご協力頂けるのであれば、検索結果と共に、問い合わせに用いた語の リストを添付して頂きたいと考えています。 リストの添付は強制ではありませんが、本ワークショップの趣旨をおくみとり頂 き、多くの皆様のご協力をお待ちしています。 以上のような問題点を含んでいますが、日本語検索特有の問題についてより進 んだ示唆を得るための一つの試みとして、今回、導入をいたしました。 ご理解とご協力をお願いいたします。 また、これについての、ご意見、議論、コメントもよろしくお願いいた します。
(iii) 日英混合文書の検索と日本語文書中の英語
インタネット上の文書も含め、日本で作成される文書集合は、基本的に日本語と英語の混 合です。英語文書は、ある場合には日英対訳あるいは日本語文書の要約として作成され、 ある場合には単独で存在します。また、日本語の文書だけをとってみても、 英語の用語が原綴あるいはカタカナ書きでしばしば現れます。しかも、それらの 用語は新語あるいは非常に専門的な語で、検索で重要な手がかりとなりうるにも関わらず、一般的な辞書やシソーラス等に載っていないこともしばしばあります。 このような日本の文書環境の特性に対処するには検索ではどのような方策が有効か? あるいは、それらの英語文書や英語の用語は無視しても充分な検索有効性を得られる のか?これらの問題に何らかの示唆が得らればと思います。
昨年のNTCIR Workshop 1では、日英対訳文書を多く含むJEコレクションを随時検索タスク (ad hoc IR task)使用しました。 しかし、データの説明が不十分だったためもあり、英語部分について積極な取り組みはほ とんどなく、英語部分を索引せず、日本語の単言語検索として行った例が多く、この問題 について十分な検討を行うことができませんでした。そこで、今回は、1文書中に日本語 部分と英語部分が含まれる対訳文書は使用せず、日本語だけあるいは英語だけの文書を対 象として、(1)単言語の検索、(2)単言語文書に対する言語横断検索、そして、(3)日本語文 書と英語文書が混ざった文書集合に対する検索というようにタスクを明確に分け、それぞ れの問題を検討したいと思います。多くのチャレンジと多面的な検討を期待しています。
(iv) 対話型検索システムへの適用
対話型システムの参加も歓迎します。対話型検索システムの評価への適用可能性、その問題点などに関する多面的な提案と検討を期待しています。
文書の種類と今後
今回の日本語・英語検索では、昨年のNTCIR-1の評価用データを用意する必要があり、 学術文書を採用しました。その特徴は以下のとおりです。
日英対訳の学術文書のテストコレクションはNTCIRの一つの特徴であり、専門用語 や未知語の扱いなど多くのchallengingは側面があります。今後は、さらに、 より広い観点から、学術論文等の全文、新聞記事、特許、Web文書、画像など対象 文書の範囲を拡大するとともに、検索された文書の活用を支援する技術の評価等に ついても示唆が得られる評価環境を整えていきたいと思います。そのためには、 著作権、専門的利用者の確保など多くの問題があります。ご協力、ご意見、コメント、 議論をお待ちしています。
なるべく早く: 参加申込(日本語・英語検索タスク) 申込期間を延長しました。
NTCIR-1は、使用許諾に必要な覚書を提出済みの参加者へお送りします。
自動要約タスクについては、後日、ご案内します。
2000年8月10日: 新しい文書と評価用検索課題の配布(日本語・英語検索タスク)
2000年9月18日: 検索結果・システム説明フォームの提出(日本語・英語検索タスク)
2001年1月10日: 正解判定結果の通知
2001年2月12日: 成果報告会のワーキングノート用仮論文の提出
2001年3月7-9日: 成果報告会(於: 東京。国立情報~学研究所一ツ橋記念大ホール)
1日目: 一般公開、 2-3日目: 結果提出者のみ
2001年3月16日: 会議録用のカメラ・レディ原稿の提出
論文と成果報告会の使用言語は英語です。
(担当:タスクの座長:神門 kando![]() )
)
自動要約タスク (automatic text summarization task): 日本語文書の要約。
テキスト自動要約タスクの目的は2つある.1つ目は,日本語テキストに対する 要約データを蓄積することであ る.残念なことに,これまで人手でテキストを要約した言語データは,日本語 に対してはごくわずかしか作成されておらず,また, 研究に利用可能なものが十分存在するという状況とは言えない.今回のタス クでは,新聞記事を対象に,人手で作成した要約データを大規模に蓄積 し,研究目的で利用に供したいと考えている.また,これまで作成されてきた 要約データは,新聞記事,特に報道記事に限定されてきた傾向が強い.今回の 要約データ作成においては,そのような現状を鑑み,報道記事だけでなく, 社説などの論説記事も対象に要約データ作成を試みる.
今回の要約データ作成ではさらに,2種類の要約を作成しようと考えている. 一つは,いわゆる重要文抽出に基づく要約であり,要約作成者に,重要な文を選択 して もらい,また,それらの重要文中の重要個所を選択してもらい,それらの重要 個所をつないだものを要約とする.二つ目は,自由作成要約である.要約作成 者に,原文にとらわれずに,自由に要約を作成してもらう.要約作成者には, 編集者,国語教師,記者など,ある程度要約という作業に熟練している方々 を依頼する.どちらの種類の要約も数百テキストの規模で作成したい.
タスクの2つ目の目的は,言うまでもなく,自動要約システムの評価である. これまで要約の評価方法にはさまざまな議論があり,また我々も実行委員 会やメイリングリストでの議論を重ねてきたが,今回は, intrinsicな評価としては,作成した要約データを用いた システムの評価を予定している.システムの評価は,依然検討 中の部分が多いが,作成した要約の種類に対応して次の2つを候補としている. 重要文抽出に基づいて作成された要約を評価に利用する場合,伝統的な評価方 法同様,人間の要約との一致度により評価を行なう. 人間の自由作成要約を評価に利用する場合,人間の要約との間の文字列上の一 致度で評価を行なうのは困難であることなどから,人間に主観的評価を行なっ てもらい,システム の要約がどの程度人間の要約に近いかで評価する.評価基準としては, 原文の重要な内容をどの程度カバーしているか,読み易さ,およびその組合せ である受容可能性が候補となる.
一方,extrinsicな評価方法としては,システムの出力 である要約を情報検索における適合性判定タスクに利用することで評価する方 法を採用する予定である. これは,1998年に開催されたTipsterのSUMMACでも評価方法の一つとして採用さ れたものである.
情報検索タスクに基づく要約の評価は基本的に次のように行なわれる. まず,人間の被験者に,検索要求とその検索結果としてテキストの要約を提示 する.被験者は各要約を読むことによって,そのテキストが検索要求に合っ ているかどうか(適合性)の判断を行う. この適合性の判断をどの程度うまく行なえたか,判断にかかった時間などを 基に,提示された要約が 良いかどうかを間接的に評価する.このことから,評価している要約の種類は, `query-biased'で,指示的(indicative)な要約と言うことができる.
情報検索用テストコレクション(検索要求,テキスト集合,適合性判定の正解)
としてどのようなものを用いるのか等未定の部分もあるが,原則的にSUMMACと
同じ方法で評価を行ないたいと考えている. 評価基準としては,タスクに要した時間および,タスクをどの程度うまく行な
えたかを示す指標として,再現率, 精度, F-measureを用いる.
再現率 = 被験者が正しく適合と判断したテキスト数/ 実際に適合するテキストの総数
精度 = 被験者が正しく適合と判断したテキスト数/ 被験者が適合と判断したテキストの総数
F-measure = 2 * 再現率 * 精度/ 再現率+精度
(担当:タスクの座長: 奥村学 (oku![]() ) または、 福島孝博 (fukusima
) または、 福島孝博 (fukusima![]() )
)
[English] [NTCIRのホーム] [ワークショップのホーム] [データのサンプル] [このページの先頭]
