B01: データ統合班
情報処理技術を活用した文理融合次世代コーパスの構築に基づくモダリティ横断

私たちは人文・理工分野の相互理解を促進させる,肝心要の研究チームです.具体的には,研究者が利用・参画可能な次世代コーパスを各研究班との協同で設計・構築します.研究環境とデータの整備を通して,様々な研究分野における身体記号への関心を誘発します.
データ統合班の研究紹介
- わたしたちデータ統合班では、既存のコーパスにはなかった情報が付与された次世代型コーパスの構築を目指します。 また、人文学的領域と理工学的領域をつなぎ、コーパスの設計やコミュニケーションの認知に必要なデータについての議論を進めていきます。
進化した第三世代のコーパス 進化した第三世代のコーパス
- データ統合班は意味の記述や記録のための従来型のコーパスを検証し、新しい世代のコーパスを構築します。
従来のコーパスは第一世代と第二世代に分類できます。第一世代は言語構造を記述する「言語学コーパス」です。第二世代は対話システムの構築等を念頭においたコーパスといえます。第二世代のコーパスには、音声だけではなく視線や姿勢、ジェスチャ等のモダリティを含む「マルチモーダル・コーパス」があります。
今回わたしたちが構築をする第三世代コーパスは、コミュニケーションの構造に関する新たなメタデータの付与された情報を提供します。これにより、現実に近く円滑なコミュニケーション理解へのアプローチが可能となります。 従来型コーパスと次世代型コーパス
従来型コーパスは主に意味の記述や貴重な言語(マイノリティ言語や消滅危機言語など)の保存などを目的として作られており、会話の「内容」や「プロセス」を記録することは必ずしも考慮されていません。
今回わたしたちが構築を目指している次世代型のコーパスでは、従来型コーパスに身体の動き等とメタデータを加えていくことで、会話において何が話されたかということの記述・収集が可能になります。従来型コーパスでは明確にしきれなかった言葉の理解のあり方に関する情報を、他研究班と協力しながら模索していきます。
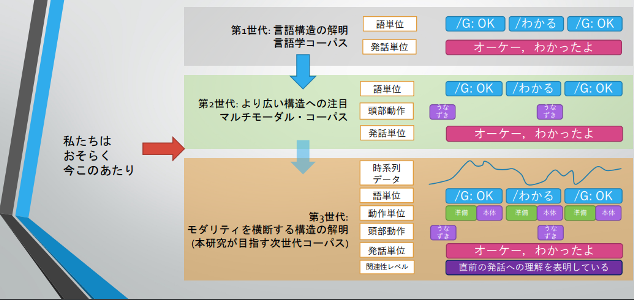
図1. コーパスの発展 ©2022 Kouhei Kikuchi次世代型コーパスの可能性
従来型コーパスの多くは、ある音声表現Aがシステム内のシンボルaと対応する(A=a)というように、音声とシンボルは一対一のセットとしてしか記述されませんでした。しかし、実際の人同士の会話では、その時々の状況、前後の発言や参加者間の関係性等により、必ずしも一つの表現に一つの意味、となるとは限りません。これをコーパスに取り入れる際、アノテーションの付与などで文脈に応じて言語や記号の意味を特定させていきます。
現状、実世界で他のどのようなモダリティと関係し合いながら人が言葉の意味を認知しているかということに関してはまだ解明されていません。言葉がどのようにして実世界と結び付くのか、また、それをAIがどのように認識するのかという問題を人工知能分野では「シンボルグラウンディング問題(記号接地問題)」と呼びます。
わたしたちは次世代型コーパスの構築によって、この問題の解決につながるさまざまな知見が得られるものと考えています。モダリティ横断コーパス
従来型のコーパス(第二世代)では語単位・発話単位・動作単位などの日常的な活動の中で用いられる音声や動作などがモダリティの一つとして記述されていますが、わたしたちが開発を目指す第三世代のコーパスでは、新たに時系列データと関連性レベルデータを従来の記述に加えるといったことを検討しています。
これらの時系列的に連続した動作のデータ(3D情報)と、前後の会話や動作との関連を含めたデータが記録されることにより、状況を構成する複数のモダリティを横断的に見渡せるようになります。
このように複数のモダリティ間の関係性・連鎖性をシステム内で関連づけながら記録していくコーパスをわたしたちは「モダリティ横断コーパス」と呼びます。
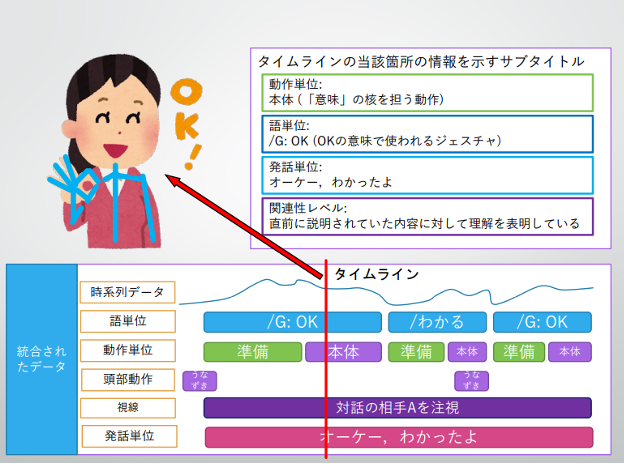
図2. モダリティ横断コーパスのイメージ ©2022 Kouhei Kikuchiデータの融合と実践
ここで重要になってくるデータが前述した2種のデータ、時系列データ(動作の一連の推移)と関連性レベルデータ(メタデータ)となります。
わたしたちが日常的に経験するコミュニケーションでは、会話の文脈、話者の態度、話者同士の関係性や環境的要因により、複数の意味合いが生じる表現があります。たとえば、「これ、おかしいね」という表現の場合、「これ」が何を指しているのかにより意味が変わりますし、「おかしいね」も面白いという意味なのか、普通ではないという意味なのかも、文脈や指し示しているものによっても変わります。
従来型のコーパスでは、こういった現実の人同士の会話の構造を記述していくことが難しいという問題点がありました。つまり、従来型のコーパスにはこれらの会話の理解にかかわるデータがありませんでした。
しかし、これらの2種のデータを組み合わせることにより、あたらしいコーパスでは従来型コーパスでは判断できなかった、会話の理解のあり方を記述することが可能になります。これにより、人の会話やコミュニケーションの構造をAIなどの機械学習に役立てることができると期待しています。
現在は収集した従来型コーパスを調査し、メタデータを記述する方法について検討しています。
また、わたしたちの研究では話し言葉と、手話をデータ化してコーパスを構築することを目指しています。将来的にはこういったデータの蓄積を通して、たとえば日本語・日本手話間の翻訳機などの開発などにも貢献できればと考えています。
人文学的知見と理工学的知見によるコーパスの設計 人文学的知見と理工学的知見によるコーパスの設計
- データ統合班は、各研究班それぞれの成果を相互に利用可能な形に「翻訳」し、整備をしていくハブとしての役割を担います。
データ統合班は既存のコーパスのアノテーションを調査・分析し、次世代コーパス構築のために必要なデータの種類を探ります。そしてその情報をA01班(身体班)とA02班(手話班)にフィードバックし、彼らはそれをもとに新たにデータを収集しアノテーションを試行していきます。わたしたちデータ統合班はこれらの情報を次世代型コーパス構築に利用します。そして機械学習や自動翻訳機開発への利用を目指すA03班(工学班)にデータを提供し、実装に向け必要なデータの収集・取捨選択を議論してすすめていきます。
このように人文学的要素と理工学的要素が存在する学際的研究を推進するうえで、わたしたちのデータ統合班は連携の土台を担い、それぞれの分野が議論を展開するプラットフォームを提供していきます。
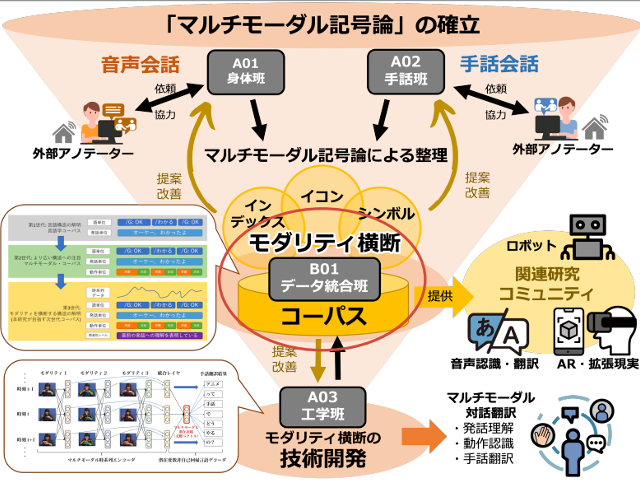 図3. データ統合班のプロジェクト内での位置づけ
図3. データ統合班のプロジェクト内での位置づけ
人文学領域と理工学領域をつなぐデータ統合班
人文学領域研究と理工学領域研究の大きな違いとして挙げられるのが研究のメソッドと得た情報の活用方法だと思います。人文学領域では内容や性質などに重点をおいた情報の取得が可能です。一方、理工学領域研究では主に数量的なデータを中心としたものとなります。データ統合班ではこれらの定性的なデータ(人文学)と定量的なデータ(理工学)を集約し、互換性を持たせます。そして、それぞれの研究班とコミュニケーション認知に必要なデータを議論して取捨選択し、それらのデータをアノテーションとしてコーパスに加え、会話や動作のデータと連携させていきます。
たとえば、わたしたちプロジェクト全体の将来的な目標の1つとして自動翻訳機の開発というものがあります。既存の機械学習や自動翻訳機では主に理工学的知見が土台にありましたが、言葉の表現の幅や意味合いやニュアンスなどが考慮されているとは言い難く、理工学系の既存の深層学習の理論では人同士の会話理解認知メカニズムに対応しきれませんでした。よって、より円滑で自然なコミュニケーションを可能にするためには人文学的知見を取り入れる必要があると考えました。
そのため、人文学研究者・理工学研究者、両者間の議論の際の共通基盤・次世代型コーパスを構築し、分野の異なる両者の相互理解を深めることで、新たな理論構築や技術開発についての議論がより一層発展していくものと考えています。最新の音声処理・動画処理技術の活用をめざして
従来のコーパス構築では発話内容や身体動作等を手作業でアノテーションの付与をしていたため、多大な労力を必要としてきました。今回の研究により、定量分析が画期的に促進されれば、こういった労力のかなりの部分は軽減されるでしょう。
次世代型コーパスの構築にあたり、最新の音声処理・動画処理技術、たとえばOpenPoseのような姿勢推定システムを用いて人の動きを解析していきます。そして、このような深層学習に基づく画像処理アルゴリズムと、表現と意味を機械処理する自然言語処理アルゴリズムと、言語哲学との融合により、手作業によるアノテーションの付与や翻訳作業などのプロセスを新しく作っていきます。また、このような新しい業務プロセスにより、より多くの研究者が次世代型コーパスの構築に積極的に参加ができるような環境づくりができればと思います。

図4. OpenPoseによる動画データ認識の一例 ©2022 Kouhei Kikuchiデータ統合班の今後の課題
先述のとおり、わたしたちの目標は次世代のモダリティ横断コーパスの構築ですが、そのためには人文・理工学分野が連携し合い、理論を構築し実践、実装へとつなげていくことが必要です。他分野との連携なしではこの目標に達することは非常に難しく、新たに異分野連携のためのメソッドを作っていくことはわたしたちにとって大きな意義があると感じています。
また、技術的な課題も存在します。既存のコーパスにはなかったデータ、複数のモダリティ間の関係性・連鎖性をシステム内で関連づける方法やそのデータの取捨選択なども今後の議論の課題となります。
これらの課題に対応し、モダリティ横断コーパスが構築されれば、人のコミュニケーションの理解がより深まることとなるでしょう。そうすることで、日本語会話と日本手話会話の機械による相互翻訳が可能となる一つの足掛かりになり、わたしたちの生活の一部として様々な分野で貢献してくれることを期待しています。
データ統合班 研究者紹介 データ統合班 研究者紹介
- わたしたちデータ統合班は本プロジェクト全体のハブとして機能し、次世代型コーパスを構築していきます。 領域の異なる分野の橋渡しや議論などを可能にするために、人文学領域と理工学領域の研究に参加することができる専門性を持ち合わせているメンバーでハイブリッドなチームを構成しています。
菊地 浩平(Kouhei Kikuchi)
筑波技術大学 助教
研究代表者
1. 専門について
研究の専門分野はコミュニケーション科学です。特に手話を用いた会話などを対象とした相互行為分析に取り組んでいます。これまでにいくつかのコーパス構築にも関わってきました。
2. この研究チームでの役割
この研究でのわたしの仕事は、次世代コーパスのスキーム (構成要素や記述の仕方など、具体的な仕様) を検討することですが、これは他の研究班との、いわば異分野連携によって達成される、わりと大がかりな仕事です。この連携のための方法論を探ることも、大きな仕事にひとつになると考えています。
3. 次世代コーパスへの期待
次世代コーパスは、例えば身体や視線の動きと、認識の変化や活動の遷移などを並列的に探索することができるものになるはずで、人の認知や認識を考える上でとても有用なものになると考えています。例えば自分が面白いと思った現象と似たような行為の連鎖 (ある参加者の発言を、通訳者が修正して通訳する) を、発言の内容や視線・身体の振る舞いなどを特徴量として探索できるとか。データの先にある面白い現象へのアクセスが、誰にとっても格段に容易になることを期待しています。岡田 将吾(Shogo Okada)
北陸先端科学技術大学院大学 准教授
研究分担者
1. 専門について
わたしの専門はマルチモーダル情報処理です。コミュニケーション中に交わされる言語・非言語情報(マルチモーダル情報)を様々なセンサで取得し、感情・個人特性といった人が内面に持つ状態・変数を理解・モデル化するための研究をしています。
2. この研究チームでの役割
この研究でのわたしの仕事は、工学的な研究での利用を想定した場合の次世代コーパスのスキーム (構成要素や記述の仕方など、具体的な仕様) の検討を行うことです。特に、機械学習等で正解データとして用いられるアノテーションをいかに適切に設計するかが重要となります。
3. 次世代コーパスへの期待
次世代型コーパスはコミュニケーション科学の研究者と、情報学、工学の研究者が共同で研究するための資産となることを期待しています。また質的な分析の研究と工学的な量的分析の研究とがうまく融合することを期待します。牧野 遼作(Ryosaku Makino)
早稲田大学 准教授
研究分担者
1. 専門について
会話や、人と人が協働してなにか一つのことを行っている相互行為(例えば,障害者と家族間で行われる食事介助や、ジャンケンなどの手遊びなど)をビデオで収録し、その中で人々の振る舞いを記述し、定性的な分析を行っています。
2. この研究チームでの役割
人々の相互行為を対象とした定性的な分析のための、どのような次世代コーパスがよいのかを検討することが役割だと考えています。相互行為の分析では、言語から始まりジェスチャー、視線、そして立ち位置の調整といった様々な身体動作が対象となってきました。研究者の目的に応じて、様々な相互行為上での人々の振る舞いが分析対象となってきます。多様な相互行為、そして多様な研究目的に応じることができるコーパスのデザイン、さらに定性的分析を行う研究者に、どのような形でコーパスのデータを提供することがよいのかを検討していきます。
3. 次世代コーパスへの期待
研究の一貫として、日本科学未来館での会話場面を収録しコーパスを作成するプロジェクトに、作業者として携わってきました。相互行為における人々の振る舞いを微細に記述することは、多くの時間と労力のかかる作業と、作業者として携わる中で実感してきました。コーパスという形で、人々の振る舞いの記述を体系的収集することは、データに対するこれまでかけた労力が、新たな研究の中で再活用され、新たな研究の契機となるという、一作業者としてはとても嬉しいことと思っております。大須賀 智子(Tomoko Ohsuga)
国立情報学研究所 特任研究員
研究分担者
1. 専門について
わたしの専門は音声情報処理です。また、音声コーパスや映像コーパスなど、民間企業からご提供いただいたデータを配布するデータリポジトリの運営にも携わっています。
2. この研究チームでの役割
本プロジェクト内では既存のコーパスを使えるようにしたり、これから作成する次世代コーパスをプロジェクト外の方まで広く使っていただけるようにしたり、といったコーパスの利用を巡る環境整備が主な役割となります。本プロジェクトで対象とするのは人の映像ですので,個人情報等への配慮も必要となります。異分野間でこのようなデータを使用するにあたり、まずはその課題の整理から必要です。将来、わたしたちの構築するコーパスが多くの方に有用なデータとなるよう、他の研究班と連携して進めていきたいと思います。
3. 次世代コーパスへの期待
今までは目視で映像を見て面白い事象を見つけても、それがたまたま起こった現象なのか、何か意図して起こった現象なのかの判断は難しかったと思います。次世代型コーパスによって、工学的な処理で同様の現象を網羅的に抽出して観察できるようになったり、そうして判明した意味のある事象をシステム的に対処できるようにしたりするなど、分析的な研究と工学的な研究とがうまく融合することを期待します。
用語集(五十音順) 用語集(五十音順)
- アノテーション:いわゆる注釈のことです。例えば「この「なんで遅れたの?」という発言は言語形式的には質問だけれど、行為としては非難をしている」といった解説のことです。
- コーパス:構造化された大量の言語資料のことを指します。構造化というのは、特に言語学的な分類 (品詞や統語的な繋がり方など) や音の産出上の特徴 (リズムやイントネーション、アクセントなど) といった言語構造に関する情報を一定の枠組みに沿って付与して行くことです。本研究では言語情報に限らず、身体を含む幅広い情報を体系的に記述することが課題のひとつとなります。
- シンボルグラウンディング問題(記号接地問題):わたしたち人間が、常に実世界との結びつきを伴って記号を用い・理解している一方、AIは記号と実世界との結びつきを理解できないことが指摘されました。1990年に認知科学者のStevan Harnardによって提示されました。 (https://arxiv.org/abs/cs/9906002)
- マルチモーダル・コーパス:コミュニケーションで用いられる様々な情報を記述したコーパスのことを指します。テキスト化できる言語情報だけでなく、抑揚やアクセントのような周辺言語や、視線やジェスチャなどの視覚的な情報など、幅広い情報を含みます。
- モダリティ:辞書的には様相・様式となりますが、コミュニケーション研究の文脈では、ある表現を成立させるひとつひとつの要素のこと、例えば発話や視線・手の動きなどを指します。
関連活動の報告 関連活動の報告
- 2023/02/29-03/01 人工知能学会 言語・音声理解と対話処理研究会第100回研究会で研究報告を行いました
tracrin2.0: 会話データの視覚表現の整形支援手法の検討
牧野 遼作(早稲田大学)、菊地 浩平(筑波技術大学)、堀内 隆仁(慶應義塾大学)
https://jsai-slud.github.io/sig-slud/100th-sig.html
- 2023/02/17 「コーパスの構築・利用と個人情報保護」についてのオンライン公開研究会を実施しました
2023年2月17日(月)に、「コーパスの構築・利用と個人情報保護」についてのオンライン公開研究会が開催されました。前半では2名が話題提供の発表をし、後半はディスカッションが行われました。
筑波技術大学の菊地浩平氏が「人文学研究での個人情報保護対応の経験から」という題で、現在コーパス構築と公開に向けてプロジェクトをすすめるなかで、個人情報の適切な取り扱いについて多くの課題に直面していると語りました。プロジェクトで扱うデータの特徴や匿名化しづらいデータを扱っているが故の懸念点等を共有しました。国立国語研究所の小磯花絵氏は「『日本語日常会話コーパス』構築・公開の経験から」という題で、過去に関わったプロジェクトの経験で参考にした法的な基準や根拠と、それをもとに対応をしてきた実例等を挙げ、本研究会のような情報共有の場を持つことの大切さについて語りました。
ディスカッションでは東京大学の宍戸常寿氏とKDDI総合研究所の加藤尚徳氏にご参加いただき、多角的な視点から個人情報を取り扱うにあたっての考え方や対応方法など詳細に渡りお話しいただきました。なお、フロアからも個人情報の匿名化の方法や協力者と良好な関係を維持しながら同意を得ることの難しさ等、興味深い意見が共有され、充実した内容の研究会となりました。
(報告詳細記事)