

データ解析の手法
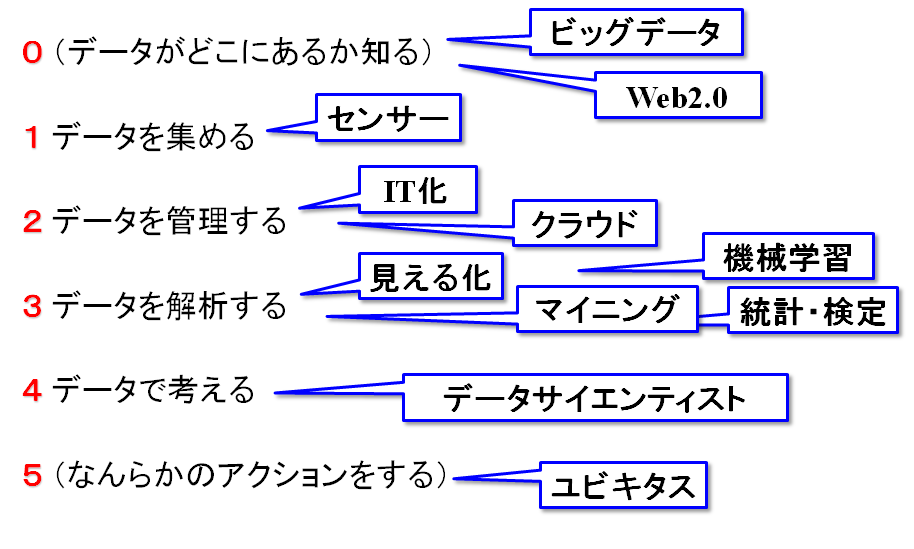 ビッグデータの解析には様々な手法がありますが、一つの手法で最初から最後まで解決するものはありません。データ解析の途中で必要となる作業、一つ一つに対して、いろいろな方法が開発されているのです。ディープラーニングがあれば、すべて解決、とはいかないのはこのためです。解析作業、図示すると図のようになります。
ビッグデータの解析には様々な手法がありますが、一つの手法で最初から最後まで解決するものはありません。データ解析の途中で必要となる作業、一つ一つに対して、いろいろな方法が開発されているのです。ディープラーニングがあれば、すべて解決、とはいかないのはこのためです。解析作業、図示すると図のようになります。
- (データがどこにあるか知る)
- データを集める
- データを管理する
- データを解析する
- データで考える
- (なんらかのアクションをする)
1から4がデータ解析の手順になりますが、実際にデータを解析する際には、「データがどこにあるかを知る」というプロセスも重要です。ここを上手にやるかどうかで、使い勝手のいいデータを使えるか、いいモデルが作れるか、という点が決まってきますので、後の効率が大きく変わってきます。最後の「アクション」は、データ解析で得られた結果をどう使うか、というところで、ここにある程度の見通しがあるのであれば、それに沿った形で解析のやりかたやデータを変えていくこともできます。
1のデータを集める、では、データの入手方法作成方法が問題になります。Webなどから手に入れられればそれでよし、お金で買うもよし、センサーをあちこちにつけて収集するもよし、探索と買い物とセンサーの問題になります。2のデータを管理する、にはデータベースやセキュリティが関係します。そのデータが大きく、頻繁にデータのあちこちにアクセスするのであれば、データベースが必要になります。逆に言えば、何回か解析するだけなら、データベースはいりません。また、個人情報などの秘匿性の高いデータの場合、セキュリティをどのように担保するか、利用する人をどのように制限し、認証するか、あるいは、個人情報が消え去るように匿名化するか、といった点が問題になります。
4のデータで考える、というところは、解析の結果出てきた解がどのような意味を持つのか、どのような理由でそのようなことが起きているのか、意味解釈や、因果関係、背後に隠れたメカニズムを推測するところです。ここは、機械的に行うのは難しいので、普通は人間が見て行います。人間が見やすいように可視化を行うことは有効です。3のデータを解析する、がここの説明でのメインになります。
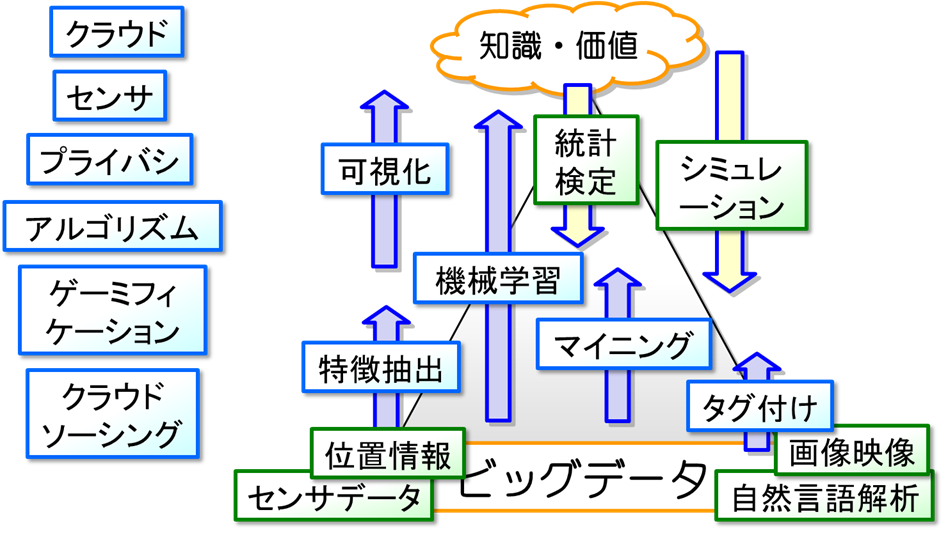 データ解析、およびその周辺にある技術を見てみましょう。図に、様々な手法を図示しました。下にあるデータから、知識をくみ上げるというプロセスの、どこにそれぞれの手法が位置するかが描いてあります。左にあるものは、いわばインフラで、計算を速くするクラウドコンピューティングやアルゴリズム、コストを下げるクラウドソーシングなど、解析手法の実行を助ける技術が並べてあります。
データ解析、およびその周辺にある技術を見てみましょう。図に、様々な手法を図示しました。下にあるデータから、知識をくみ上げるというプロセスの、どこにそれぞれの手法が位置するかが描いてあります。左にあるものは、いわばインフラで、計算を速くするクラウドコンピューティングやアルゴリズム、コストを下げるクラウドソーシングなど、解析手法の実行を助ける技術が並べてあります。
ビッグデータ時代が昔と大きく違うところは、昔はデータが中段くらいにあった、つまり各項目の意味がとりやすく、知識に近かったことだと思います。たとえば、一日の行動を調べる場合、今はスマホなどのGPSセンサを利用します。これだと、非常に密度が濃く、正確ですが、スマホの持ち主が何をしているかは、まったくわかりません。昔はアンケートなどを使っていましたが、その際には、食事をした、電車で移動した、など、意味がとりやすい行動データがとられていました。意味がわかりやすいデータ、あるいは多様性の小さいデータであれば、統計やシミュレーション、可視化といった技術をそのまま適用しても、意味が十分わかりやすい解が得られます。しかし、意味解釈の難しい、GPSのデータを直接使って、たとえば渋谷に来る人は、この点とこの点を踏むことが多い、などというルールを発見しても、それが何を意味するのかさっぱりわからず、意味解釈に苦労します。一人の人が踏んだ場所は大量にあるので、その中でどこが重要なパターンになっているかを調べるのも大変です。ここがビッグデータ時代の大きな困難です。そこで、意味解釈がしやすいように、様々な属性からその特徴を表すものを抽出する特徴選択、特徴的な構造を取り出すマイニング、データに意味を示すラベルをつけるアノテーションなどを使い、わかりにくい生のビッグデータを、ある程度意味がとれるようなデータに変える作業が必要となります。これが、ビッグデータでのデータ解析の大きな特徴の1つです。
このようにして得られた意味のとりやすいデータ、あるいは生のデータから直接、ルールや相関、分類などを見つけ出すのがデータ分析の手法になります。解析手法には、大きく分けて教師ありのものと教師なしのものがあります。教師ありとは、正解がわかっているもののことをいいます。たとえば、人の顔の画像データから、人の顔の特徴を抽出したり、人の画像とそうでない画像を分けるルールを見つけたい場合、最初に与えるデータには、この画像は人の画像かどうか、あるいは人の顔はどこに写っているのか、正解が与えられるわけです。このような正解のあるデータから、予測手法や認識ルールを見つけ出すことを、「教師あり学習」といいます。教師あり学習は、データが作られるメカニズムにある程度のあたりがついている場合とそうでない場合があり、あたりがついていれば統計・検定が解析に使われ、そうでなければ機械学習が使われます。教師なし学習は、正解のない、つまり目的のはっきりしないタスクに対して解析を行うもので、買い物データやGPSの位置情報データなどから、何か特徴的なものを見つけ出そう、データが全体的にどうなっているのか理解しよう、というようなときに使います。Web検索をするときに、検索したいものがわかっており、キーワード検索などで見つけにかかるのが、正解がある場合、何か面白そうなものを探して、ネットサーフィンするような場合が、正解なしと考えると、わかりやすいと思います。教師なし学習は、部分的な構造やデータの妥当な分割など、正解はわからないが、見つけたいものの種類がわかっているときには、マイニングを使い、わからないときには、可視化を使います。以下で、この4つの手法について、解説しましょう。
統計・検定
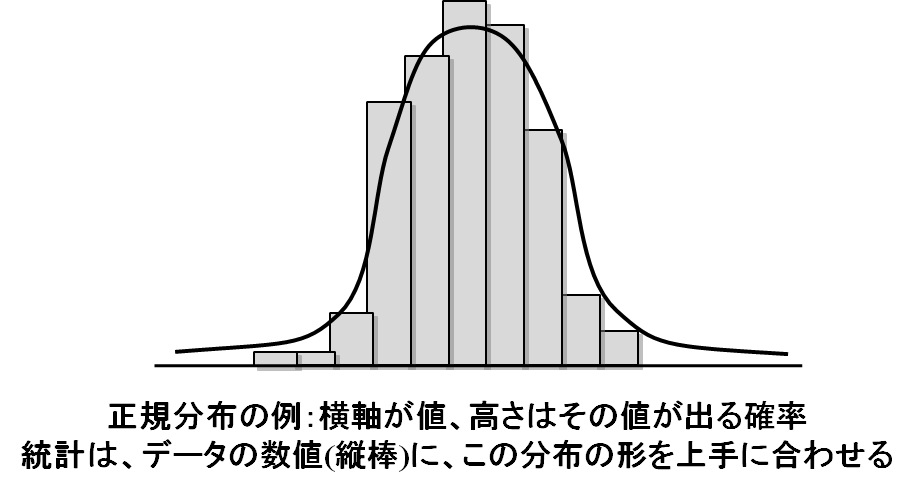 統計は、データはある種の生成モデルのもとでランダムに発生するものである、という、ある種の真理を仮定してデータを解析する手法です。たとえばコインを10枚投げて表が出る枚数、というデータをとると、これは図の曲線のような、正規分布とよばれる分布になります。分布とは、それぞれの出来事がどれくらいの確率で起きるか、というものを表したものです。たとえば、コインの場合、一枚も表が出ないか確率は1/1024、1枚だけ表がでる確率は10/1024、といった具合です。たとえばデータのある数値が、これと同じような確率で発生していたら、コインを10枚投げる(正解/不正解があるものを10回行って、成功した数、のような感じ)のと同じメカニズムででてくる数字なのではないか、と考えられるわけです。ただし、確率はあくまで確率で、実際に10回コインを振ってもっとも高い数字が出るとは限りません。数字が1である確率はどれくらいか、2である確率はどれくらいか、をデータの中で数字が1であった回数を調べて推測します。これで、データの数値が、「10コインを振って表が出た回数」と本質的に同じ仕組みで生成されたかどうかがわかります。さらに、コインを振る回数が違っても、分布の形は同じようになりますので、何回コインを振った結果なのか、もわかりますし、表が出たら10点、裏が出たら3点、のように得点が異なっている場合も、数値の平均を見ることで、得点がどのようになっているのか推測することができます。このように「こういう形で作られた数値」であると仮定し(モデルを決める、といいます)、その分布を得点や回数などのパラメータ、図でいえば横方向にどれだけずらすか、高さをどれだけ引き延ばすかなど、をデータにもっとも当てはまりが良くなるように調製することで、数値が作られるメカニズム(仕組み)を知ること、それを平均や分散などの数値から理解するのが統計のねらいです。
統計は、データはある種の生成モデルのもとでランダムに発生するものである、という、ある種の真理を仮定してデータを解析する手法です。たとえばコインを10枚投げて表が出る枚数、というデータをとると、これは図の曲線のような、正規分布とよばれる分布になります。分布とは、それぞれの出来事がどれくらいの確率で起きるか、というものを表したものです。たとえば、コインの場合、一枚も表が出ないか確率は1/1024、1枚だけ表がでる確率は10/1024、といった具合です。たとえばデータのある数値が、これと同じような確率で発生していたら、コインを10枚投げる(正解/不正解があるものを10回行って、成功した数、のような感じ)のと同じメカニズムででてくる数字なのではないか、と考えられるわけです。ただし、確率はあくまで確率で、実際に10回コインを振ってもっとも高い数字が出るとは限りません。数字が1である確率はどれくらいか、2である確率はどれくらいか、をデータの中で数字が1であった回数を調べて推測します。これで、データの数値が、「10コインを振って表が出た回数」と本質的に同じ仕組みで生成されたかどうかがわかります。さらに、コインを振る回数が違っても、分布の形は同じようになりますので、何回コインを振った結果なのか、もわかりますし、表が出たら10点、裏が出たら3点、のように得点が異なっている場合も、数値の平均を見ることで、得点がどのようになっているのか推測することができます。このように「こういう形で作られた数値」であると仮定し(モデルを決める、といいます)、その分布を得点や回数などのパラメータ、図でいえば横方向にどれだけずらすか、高さをどれだけ引き延ばすかなど、をデータにもっとも当てはまりが良くなるように調製することで、数値が作られるメカニズム(仕組み)を知ること、それを平均や分散などの数値から理解するのが統計のねらいです。
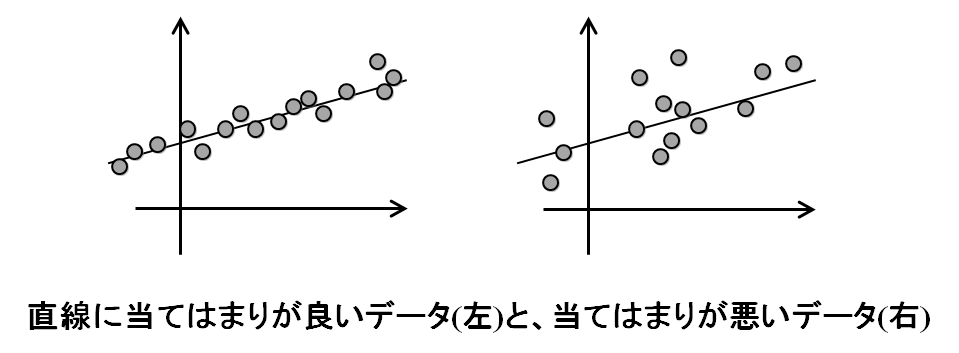 統計は、データを分布に当てはめますが、無理矢理当てはめれば、どのようなデータでも一番もっともらしい当てはめ方を見つけることはできます。もちろん、全然当てはまらないわけですが。この「当てはまり度合い」を調べ、はたしてこの当てはめ方は良いのだろうか、最初に「このデータはこの分布だろう」と思ったところが間違っていないか、を調べるのが、検定になります。たとえば、データの数値を図にプロットしてみて、直線上にきれいに乗っていれば、あ、このデータは直線上に分布しているな、と考えられます。逆に、直線から離れた数値が多ければ、ほんとに直線上にのっているのか、怪しいな、と考えられます。この、直線からデータがどれくらい離れているか、一般的には、分布の曲線からデータがどれくらい離れているか、を計算して評価するのが検定です。当てはまり度合いが悪ければ、最初の仮定、このデータはこういう分布なのだろう、という見立てが間違っていたことになりますし、見立てがよければ、データはきっちり当てはまります。また、データにノイズが乗っていたり、他の要因でデータの数値が多少増減する場合には、当てはまり度合いを見ることで、ノイズの大きさや他の要因の影響の大きさを見ることもできます。
統計は、データを分布に当てはめますが、無理矢理当てはめれば、どのようなデータでも一番もっともらしい当てはめ方を見つけることはできます。もちろん、全然当てはまらないわけですが。この「当てはまり度合い」を調べ、はたしてこの当てはめ方は良いのだろうか、最初に「このデータはこの分布だろう」と思ったところが間違っていないか、を調べるのが、検定になります。たとえば、データの数値を図にプロットしてみて、直線上にきれいに乗っていれば、あ、このデータは直線上に分布しているな、と考えられます。逆に、直線から離れた数値が多ければ、ほんとに直線上にのっているのか、怪しいな、と考えられます。この、直線からデータがどれくらい離れているか、一般的には、分布の曲線からデータがどれくらい離れているか、を計算して評価するのが検定です。当てはまり度合いが悪ければ、最初の仮定、このデータはこういう分布なのだろう、という見立てが間違っていたことになりますし、見立てがよければ、データはきっちり当てはまります。また、データにノイズが乗っていたり、他の要因でデータの数値が多少増減する場合には、当てはまり度合いを見ることで、ノイズの大きさや他の要因の影響の大きさを見ることもできます。
データがいくつかの分布の重ね合わせでできていると考えられる場合、この当てはめの作業も、2つの分布を重ねたときにもっともデータの数値と当てはまりが良くなるような当てはめ方を探します。たとえばデータにうまくいっているときと、調子が悪いときの数値が入っていて、お互いに異なる分布をしていると考えられるならば、その2つの分布を両方一度に当てはめて推定します。こうすることで、新しい、調子が良いのか悪いのかわからないデータがやってきたときに、数値を見ることで、調子がいい確率がこれくらいで、悪い確率がこれくらい、と推定・予測することができます。当てはめた分布を見れば、その数値が出たときは、調子がいい確率がこれくらい、悪い確率がこれくらい、と見積もれますので、それを使って、いい悪いを推定できるからです。
機械学習
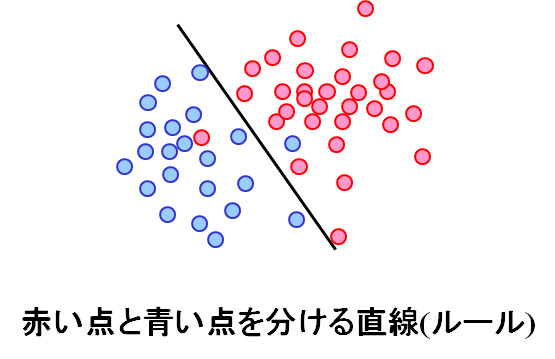 統計が分布、というモデルを仮定するのに対して、機械学習はそのようなモデルを仮定しないで解析を行う方法です。機械学習は、調子が悪い、調子が良い、のように、2種類のデータ、あるいは数種類のデータがあるときに、それらを分類するルールを見つける方法です。たとえば、図には赤い点と青い点が散っていますが、図の黒い直線でだいたい分けられます。これを見れば、次にやってきたデータの数値が線の右上にあれば赤だろうし、左下にあれば青だろうな、と推定・予測できます。統計の場合は、赤の点の分布と青の点の分布を両方求めることで、どこが赤/青の領域かを調べますが、機械学習では、図の直線のような分類ルールを、データの点を最も上手に分類するように調製することで、直接見つけ出します。統計では、点がどのような分布になっているか、すなわちどのように作られているのかがわからないといけなかったのですが、機械学習はデータだけあれば良いのがメリットです。しかし、統計では、青である確率が○○%、というように確率まで出ていたのに対して、機械学習では根拠のある確率を求めるのはそれほど簡単ではありません。
統計が分布、というモデルを仮定するのに対して、機械学習はそのようなモデルを仮定しないで解析を行う方法です。機械学習は、調子が悪い、調子が良い、のように、2種類のデータ、あるいは数種類のデータがあるときに、それらを分類するルールを見つける方法です。たとえば、図には赤い点と青い点が散っていますが、図の黒い直線でだいたい分けられます。これを見れば、次にやってきたデータの数値が線の右上にあれば赤だろうし、左下にあれば青だろうな、と推定・予測できます。統計の場合は、赤の点の分布と青の点の分布を両方求めることで、どこが赤/青の領域かを調べますが、機械学習では、図の直線のような分類ルールを、データの点を最も上手に分類するように調製することで、直接見つけ出します。統計では、点がどのような分布になっているか、すなわちどのように作られているのかがわからないといけなかったのですが、機械学習はデータだけあれば良いのがメリットです。しかし、統計では、青である確率が○○%、というように確率まで出ていたのに対して、機械学習では根拠のある確率を求めるのはそれほど簡単ではありません。
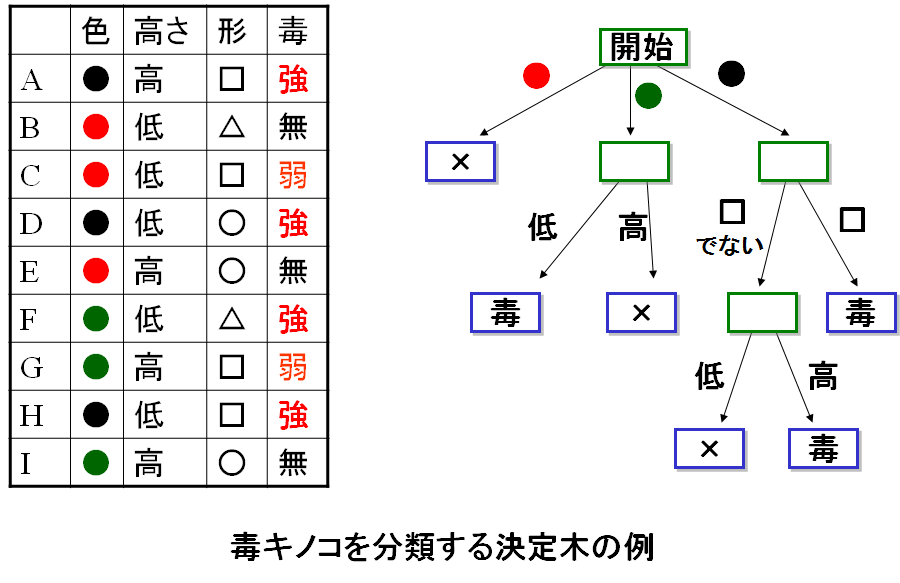 データを分けるルールとしては、直線や曲線、平面や論理式、性格判断のチャートのようなものまでいろいろあります。特にチャート型のものは、決定木とよばれます(例:右図)。ルールが複雑になればなるほど、データを上手に分けられるようになります。たとえば、くにゃくにゃした線を使っていいのであれば、図の、分け損なっている青い点と赤い点も、分けることができますが、かなり無理矢理感のある分け方になるでしょう。そもそも、図のデータは線のところでだいたい赤と青が分かれていると考えるのが自然ですし、よほど変な理由がない限り、分け損なっている赤(青)の点の周辺も、その周りがみんな青(赤)の点なのですから、そこも青(赤)になっているのでしょう。それを、無理矢理データにあわせて凝った分類ルールを作ってしまうと、かえって、新しいデータに対する予測の精度が落ちてしまうこともあるのです。その意味で、あまり凝ったことをせず、単純に攻めた方がいい、という経験則もあるのです。このあたり、高度なものを使えば精度が上がるはず、という直感に反するのが面白いところですね。
データを分けるルールとしては、直線や曲線、平面や論理式、性格判断のチャートのようなものまでいろいろあります。特にチャート型のものは、決定木とよばれます(例:右図)。ルールが複雑になればなるほど、データを上手に分けられるようになります。たとえば、くにゃくにゃした線を使っていいのであれば、図の、分け損なっている青い点と赤い点も、分けることができますが、かなり無理矢理感のある分け方になるでしょう。そもそも、図のデータは線のところでだいたい赤と青が分かれていると考えるのが自然ですし、よほど変な理由がない限り、分け損なっている赤(青)の点の周辺も、その周りがみんな青(赤)の点なのですから、そこも青(赤)になっているのでしょう。それを、無理矢理データにあわせて凝った分類ルールを作ってしまうと、かえって、新しいデータに対する予測の精度が落ちてしまうこともあるのです。その意味で、あまり凝ったことをせず、単純に攻めた方がいい、という経験則もあるのです。このあたり、高度なものを使えば精度が上がるはず、という直感に反するのが面白いところですね。
機械学習の中でも、人間の脳みその仕組みを模して考えられているのが、ニューラルネットとよばれるものです。人間の脳みそは、神経細胞がネットワークを作っていて、神経細胞が反応すると、その反応がつながっている他の神経細胞に、シナプスとよばれる仕組みで伝達するようになっています。神経細胞は複数の神経細胞とつながっていて、どこから刺激を受けると、どこにシナプスが行くか、というルールが、神経細胞ごとに決まっているようで、そのおかげで複雑な信号処理が、脳みその中で行えるようです。ただ、このあたりの仕組みは、細胞の働きとしてはわかっているのですが、実際にどういう反応がおこったら、ものが理解できているのか、あるいはものを見たと認識できるか、というソフトウェアのレベルの話は、まだほとんど解明されていないようです。仕組み自体はわかっているので、この仕組みをまねしよう、というのがニューラルネットのアイディアです。
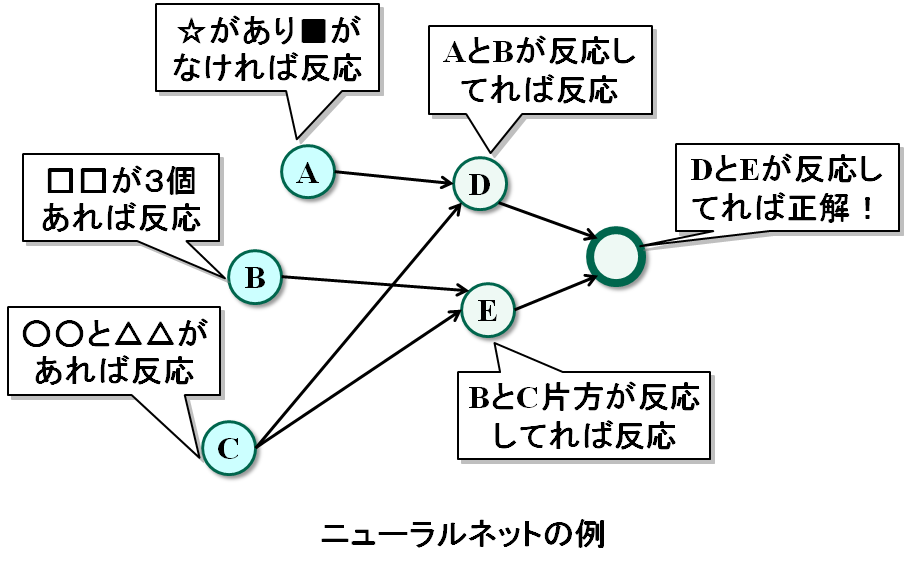 ニューラルネットは、データの各項目や、データから取り出したデータの特徴に対してネットワークを作り、正解のデータが来たら反応して、不正解のデータきたら反応しないようにネットワークの反応の仕方を調製することで、脳みそが行うような正確な予測、とくに認識や認知の問題を解きます。たとえば、図のように、短い文章のデータから、単語を取り出して、「この単語とこの単語が含まれていたら細胞Aが反応」「この単語が3回現れたらBが反応」「Aが反応しててBが反応してなければ、Cが反応」のようになります。上手にネットワークを最適に調製することで、複雑な認識プロセスが必要なものでも認識でき、予測精度も上がると考えられます。この、ニューラルネットワークを巨大化したものが、ディープラーニングです。
ニューラルネットは、データの各項目や、データから取り出したデータの特徴に対してネットワークを作り、正解のデータが来たら反応して、不正解のデータきたら反応しないようにネットワークの反応の仕方を調製することで、脳みそが行うような正確な予測、とくに認識や認知の問題を解きます。たとえば、図のように、短い文章のデータから、単語を取り出して、「この単語とこの単語が含まれていたら細胞Aが反応」「この単語が3回現れたらBが反応」「Aが反応しててBが反応してなければ、Cが反応」のようになります。上手にネットワークを最適に調製することで、複雑な認識プロセスが必要なものでも認識でき、予測精度も上がると考えられます。この、ニューラルネットワークを巨大化したものが、ディープラーニングです。
ディープラーニングは、簡単に言えば、1970年代に開発されたニューラルネットを複雑に階層化したものです。当時からアイディアはあったのですが、複数の階層が作り出す複雑なネットワークで、最適な学習をさせる最適化技術とコンピューターパワーがなかったので、当時はその威力が検証できませんでしたし、実際に計算を行う際に発生する問題点もわかっていませんでした。図のニューラルネットでは、データから正解の場所(ノード)まで3回の移動でたどりつける、つまり3階層のネットワークになっています。この階層をもっと大きく、20や40にして、データに対する学習能力を高め、より複雑なものを精度高く認識できるようにしようというのがディープラーニングです。ただ、これだけ深い階層のネットワークを最適化するのは、計算がものすごく大変になりますので、通常はある程度関係なさそうなノードをばっさり、それこそ99.99%のリンクを省略した状態から出発してネットワークの最適化を行います。1つのノードから出ているリンクが10本程度になっても、それでも計算のコストは大変なものです。なので、ネットワークの形はある程度こうなるだろう、と予想されるものでしか、現在のところは威力を発揮できていませんが、うまく行く場合は、今までの方法に比べて格段に精度の高い予測や認識ができるようになります。
たとえば、写真に何が写っているかを認識するルールを、ディープラーニングで計算(学習)させるときは、写真の画素をデータとして、ネットワークを作ります。画像の場合、だいたいは隣り合った画素が集まって部分を構成して、その部分的な絵なり物体なりがつながって、全体を構成しています。ですので、ディープラーニングのネットワークも、隣あうところにしか、リンクを張る必要がないだろう、と考えられます。実際、このようにして得られたルールを使えば、猫や犬など、今まで認識が難しかったものが認識できるようになることがわかっています。音声のデータも同じです。時間的に隣り合った音が集まって部分を作り、その部分的な音が集まって音声を構成しますので、音声認識がディープラニングで精度高く学習できるのです。しかし、複雑なネットワークを最適化するには多くのパラメータを最適に調整する必要があり、そのためには大量のデータが必要になります。ディープラーニングは、大量のデータがないと動かないのです。
マイニング
統計と機械学習が教師付き、正解不正解を予測するための手法であるのに対して、マイニングは何もわかっていないところで、興味深いものを見つけるための手法です。マーケッティングや、実験データからなんらかの法則(仮説)を見つけたいときには、何が正解で何が不正解かわからず、そもそも何を見つけたいのか、データ解析をするユーザさえもわからないことが多いものです。そんなときでも、たとえばこんなことをしてみて、どんな解が出てくるか様子を見てみる、という方向で解析を行うのがマイニングです。ただし、本当に何もわからなければどうしようもないので、自分の興味の片鱗だけは決めることにします。たとえば、位置情報データから、人の動きの流れのようなものを見つけたいとか、似ている顧客を集めて分類してみたいとか、集中して検索されているキーワードを見つけたいとか、そのようなものです。ここでキーワードとなるのが、流れ、似たもの、集まり、集中、など、状態や性質を概念的に表す言葉です。この言葉を核にして、データから興味深いものを見つけていきます。つまり、データから「似たものを見つける」「似たものが集まったグループを見つける」「あるていど全体的な流れを見つける」「時間的に集中しているものを探す」といった具合です。これなら、見つかったものは十分に興味深いでしょうし、解析でやることもある程度見えてきます。
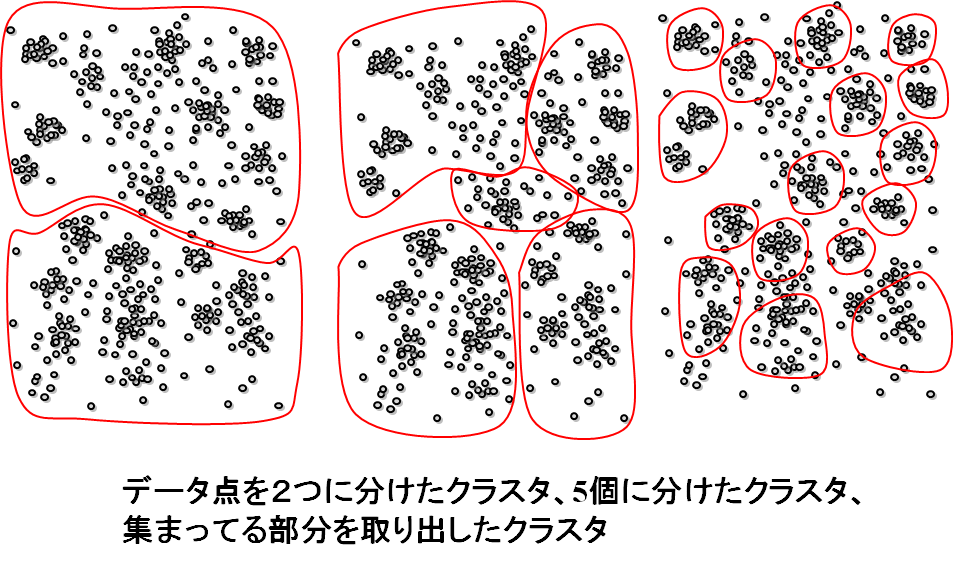
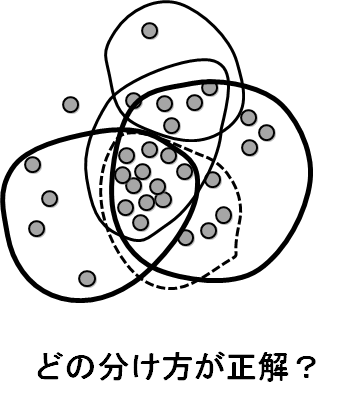 似たものが集まったグループを見つける、あるいはデータをいくつかのグループに分ける、といった問題はクラスタリングとよばれます。見つけたグループはクラスタといいます。どう分ければよいか、正解がないので、こうなっているであろう、という根拠を求め、なるべく2つのクラスタの間のギャップが大きくなるように分ける、なるべくクラスタが丸に近い形をするようにする、クラスタの中心から近いものが他のクラスタに属さないようにする、などの基準を設けて、上手な分け方を見つけます。クラスタをたくさん見つける場合は、お互いに似ているもののグループを見つける、といった方法がとられます。少数に分けるタイプの研究が多くなされている一方、たくさんのクラスタを見つける方の研究は少なめです。グループがある程度できたとして、そのグループに、グループの一部とは似ているが、残りとは似ていないものを入れるか入れないか、といった判断が難しく、逆に、それを入れて、似てないものを抜く、といったように入れ方を変えると似たようなグループが大量にできてしまい、どれが一番良いのかわからなくなるのです。
似たものが集まったグループを見つける、あるいはデータをいくつかのグループに分ける、といった問題はクラスタリングとよばれます。見つけたグループはクラスタといいます。どう分ければよいか、正解がないので、こうなっているであろう、という根拠を求め、なるべく2つのクラスタの間のギャップが大きくなるように分ける、なるべくクラスタが丸に近い形をするようにする、クラスタの中心から近いものが他のクラスタに属さないようにする、などの基準を設けて、上手な分け方を見つけます。クラスタをたくさん見つける場合は、お互いに似ているもののグループを見つける、といった方法がとられます。少数に分けるタイプの研究が多くなされている一方、たくさんのクラスタを見つける方の研究は少なめです。グループがある程度できたとして、そのグループに、グループの一部とは似ているが、残りとは似ていないものを入れるか入れないか、といった判断が難しく、逆に、それを入れて、似てないものを抜く、といったように入れ方を変えると似たようなグループが大量にできてしまい、どれが一番良いのかわからなくなるのです。
 データの中にたくさん現れるもの(パターン)は、頻出パターンとよばれます。頻出パターンをデータからすべて見つけ出すのがパターンマイニングです。スーパーマーケットの売り上げデータを考えてください。お客さんの一回の買い物、つまり買い物かごの中身、は品物のリストと考えられます。売り上げデータは、たとえるなら、品物リストが買い物客の数だけ集まったものと考えられますね。ここで、多くのお客さんに共通して買われている品物の組合せ、つまり、多くのお客さんの買い物かごリストの中に含まれている組合せは、よく一緒に売れているのだと考えられます。つまり相関、共起性が高いのです。こういった、たくさんの項目に含まれるような組合せ(パターン)が頻出パターンです。頻出パターンを見れば、たとえば、おにぎりを買ったお客さんはお茶を買いやすいとか、おにぎりとお茶は、カテゴリが同じ商品(同じ好み)だと考えられます。また、お茶とおにぎりを同時に買うのは、ある種の典型的な買い方なのだな、と思えますし、同時に買っているお客さんは、そういう嗜好を持った人たちのグループなのだろうなと考えられます(このような分類をバイクラスタリングとよびます)。頻出パターンは様々な使い方がありますが、すべてのパターンを見つけると100万なり1億なりの数のパターンがでてくることも珍しくなく、その中でどのパターンが重要かを判別するのも難しいため、このあたりに取り扱いの難しさがあります。
データの中にたくさん現れるもの(パターン)は、頻出パターンとよばれます。頻出パターンをデータからすべて見つけ出すのがパターンマイニングです。スーパーマーケットの売り上げデータを考えてください。お客さんの一回の買い物、つまり買い物かごの中身、は品物のリストと考えられます。売り上げデータは、たとえるなら、品物リストが買い物客の数だけ集まったものと考えられますね。ここで、多くのお客さんに共通して買われている品物の組合せ、つまり、多くのお客さんの買い物かごリストの中に含まれている組合せは、よく一緒に売れているのだと考えられます。つまり相関、共起性が高いのです。こういった、たくさんの項目に含まれるような組合せ(パターン)が頻出パターンです。頻出パターンを見れば、たとえば、おにぎりを買ったお客さんはお茶を買いやすいとか、おにぎりとお茶は、カテゴリが同じ商品(同じ好み)だと考えられます。また、お茶とおにぎりを同時に買うのは、ある種の典型的な買い方なのだな、と思えますし、同時に買っているお客さんは、そういう嗜好を持った人たちのグループなのだろうなと考えられます(このような分類をバイクラスタリングとよびます)。頻出パターンは様々な使い方がありますが、すべてのパターンを見つけると100万なり1億なりの数のパターンがでてくることも珍しくなく、その中でどのパターンが重要かを判別するのも難しいため、このあたりに取り扱いの難しさがあります。
このほかにも、化合物のデータベースから特徴となる部分構造を見つけたり、位置情報データから群れをなして動いているグループを見つけ出したり、マイニングには様々なタスクがあります。肝心なのは、マイニングが見つけるのは、ある種の部分的な構造だけなので、それを直接的に何かに使うのは、普通は難しいということです。最初の図でも示しましたが、マイニングはあくまで他の手法の補助の意味合いが強いです。直接的にデータからルールを見つけても、「A地点を踏んだ人は、確率1.2%でB地点を踏む」のように、何を意味するのかわからないものが出てくることが多いものです。他の手法を利用するなどして、意味解釈を上手に行うことがポイントとなります。
可視化
可視化は、データを解析する作業を、コンピュータがやるのではなく、人間にまかせるときに使う手法です。人間は高い解析能力を持っていますが、コンピュータのように大量のデータを処理したり高速に正確に計算することは苦手ですし、そもそもそういう単純処理を大量にすることは、普通はいやがられます。データの解析ではそのような単純な処理がたくさんあるため、普通はコンピュータに作業をある程度まかせるのです。しかし、原因と結果の関係(因果関係)や、同じ時に起こりやすい事柄(相関関係)を把握して、どこがどうなってこのようなデータができているのかを判断するのは、やはり人間が圧倒的に上手です。この、人間にとっていやな作業を軽減し、判断や理解がしやすいように、データを加工することが、可視化になります。広くとらえれば、平均や分散を計算したり、データの項目数を勘定して表示することも可視化になります。年代ごとの割合や、Yes/Noの割合を円グラフで描いたり、株価の推移を折れ線グラフやローソクで表しているのも可視化です。
しかし、グラフや数値では、多様性の高いデータの全体的な像をとらえることができません。まさに、ビッグデータで必要とされていることが難しいわけです。ネットワークや位置情報データのように、数値だけでは表しにくいものもあります。そういったものを、画像や動画、時には音声も使って表示することで、データの特徴や全体的な傾向をわかりやすくします。たとえば、ネットワークを表示するときに、適当な場所にノードをおいて描画すると、線がぐちゃぐちゃに交差してしまい、何が何だかわからなくなります。会社組織や高校野球のトーナメントのような、階層的な構造をしているのですが、各階層にノードを置けば見やすくなります。リンクがたくさん入り組んで集中しているところがあるなら、そこはひとまとまりにしてしまえば見やすくなります。こうやって、コミュニティ構造や階層構造、全体的な流れやハブといったものを明確に表示することで、ネットワークの全体像がとらえやすくなるわけです。
ネットワーク描画の他にも、多様で様々なものたちの全体像をとらえるために類似したものがそばに来るように画面上に配置するSOM、場所ごとの集中度合いや活性化度合いなどを色の変化で表示するヒートマップ、ネットワークやデータを3次元に配置して、ユーザの操作により視点を変えて表示する3次元表示、ユーザの着目点の変化に合わせて見ている部分を次々に移動させていくブラウジングなど、様々な手法があります。データの配置自体も、わかりやすくするためには難しいのですが、そのほかにも補助的なラベルやなんらかの評価値や最高・最悪の可能性の表示、グラフィックやアニメーションなど、様々な技術が必要であり、総合的な技術になります。