

学術でのビッグデータ
自然科学、社会科学、工学や芸術にいたるまで、様々な分野にデータは存在します。そのデータを使えば、今までにない研究が行えますし、新しい知見が得られる可能性があります。ただし、データは万能ではありません。データの保存から利用まで、データの持つ意味や価値を理解し、何をどのように研究するかを考えなくては、ゴールを外してしまいます。精度の高い解析技術を使い、開発することも重要ですが、データの選別から課題の設定にいたるまでの周りにあるタスクをしっかりこなすことも重要です。
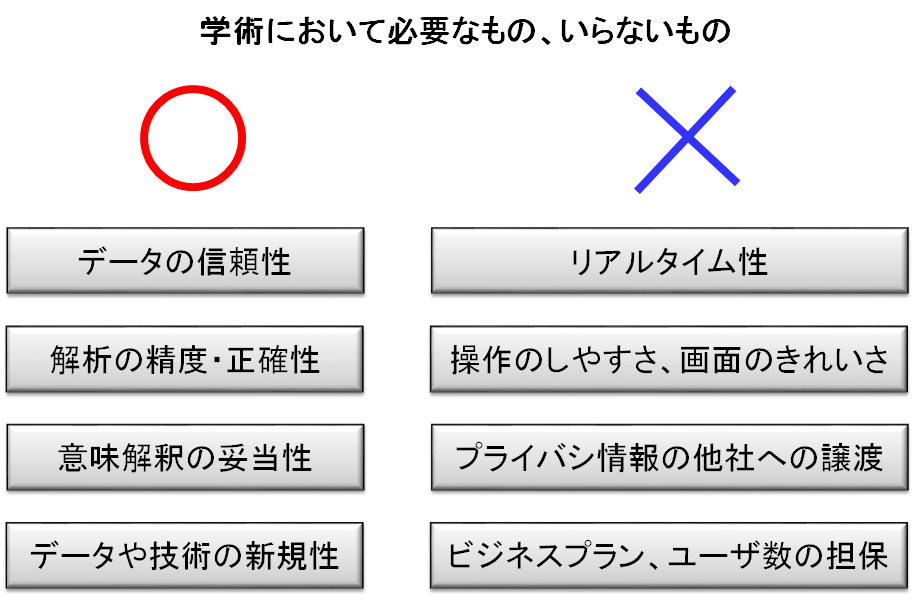
考えるにあたって、まず押さえておきたいことがいくつかあります。1つ目は、学術的知識を得るという作業は、産業におけるサービスの展開とは違いますので、産業界で言われているような技術は不要であることが多い、ということです(学祭向けのサービスを使用としている場合は別です)。たとえば、様々なデータをリアルタイムに収集してその場で顧客に情報提供する、というサービスをするには、大量のセンサからデータを集める、センサ技術、通信技術に加え、速度が速く大きいデータベース、解析をリアルタイムで行う高速アルゴリズムなどが必要となります。しかし、学術的知識を得る場合は、リアルタイムでデータを追加する必要は薄く、通常は過去のある一定期間のデータ、あるいはすでに収集されたデータを利用します。この場合には、リアルタイム性を考慮する必要はなく、上記技術も不要となります。また、プライバシーに気を配る必要もない場合が多く、データや解析結果の秘匿性に関しても、むしろオープンにしたい場合が多いため、考慮する必要がありません。不要な部分を考える範囲から捨て去ることがまず大事です。
次は、データ解析においては、分析対象、生物であるとか画像であるとか、よりも、どのように調べたいか、つまり何の性質を知りたいか、めずらしいものを見つけたいのか、検証がしたいのか、仮説を発見したいのか、のほうが重要であるということです。これは、データ解析が「手法」であり、有効な手法を選ぼうとしているからです。画像から何かを認識したいのであれば、対象はどのような生物でも、技術的にあまりかわりありません。検証や分布推定をしたい場合もそうです。物理のデータでも化学のデータでも、技術的に大きな異なりはありません。どのようなことを調べたいか、のほうが重要なのです。
 さらに、ビッグデータ、という観点であれば、論点が変わってきます。
自分の持つ仮説が正しいかどうかを検証したい、という場合、まずはそのデータが正しいかどうかが重要になります。たとえば、湿度が高い場合の現象を調べたいときには、湿度計を設置して湿度を記録し、湿度が高い場合のデータのみを使えば、正しく湿度が高い状態の現象がわかります。しかし、葉に水滴が付いている場合の植物の状態のデータをとりたいときに、湿度が高ければ水滴が付くだろう、と仮説を立ててデータをとっても、果たしてそれが本当かどうかわかりません。湿度が高いことと水滴が付くことに相関はありますが、それが100%の相関というわけでもありませんし、気温という他のパラメータも影響するでしょう。気温が植物の状態に何らかの影響を与えるのであれば、水滴と植物の状態に何の関係がないとしても、気温を通じて両者はおかしな相関することになり「なんか関係あるのでは」という間違った仮説を導いてしまいます。このように、まずは正しいデータを得ること、あるいは確率的な推測が入っているのであれば、それが観測したい事柄と確率的に独立であることを示す必要があり、いろいろと大変です。ビッグデータの使い方、その王道は、うっすらとしたもの(関係性など)を見つけたい、というところにあると考えるのであれば、検証にビッグデータ的なアプローチをすることは、あまり賢いとはいえないでしょう。ビッグデータから、確かな部分だけを抽出して使う、というアプローチにするべきです。
さらに、ビッグデータ、という観点であれば、論点が変わってきます。
自分の持つ仮説が正しいかどうかを検証したい、という場合、まずはそのデータが正しいかどうかが重要になります。たとえば、湿度が高い場合の現象を調べたいときには、湿度計を設置して湿度を記録し、湿度が高い場合のデータのみを使えば、正しく湿度が高い状態の現象がわかります。しかし、葉に水滴が付いている場合の植物の状態のデータをとりたいときに、湿度が高ければ水滴が付くだろう、と仮説を立ててデータをとっても、果たしてそれが本当かどうかわかりません。湿度が高いことと水滴が付くことに相関はありますが、それが100%の相関というわけでもありませんし、気温という他のパラメータも影響するでしょう。気温が植物の状態に何らかの影響を与えるのであれば、水滴と植物の状態に何の関係がないとしても、気温を通じて両者はおかしな相関することになり「なんか関係あるのでは」という間違った仮説を導いてしまいます。このように、まずは正しいデータを得ること、あるいは確率的な推測が入っているのであれば、それが観測したい事柄と確率的に独立であることを示す必要があり、いろいろと大変です。ビッグデータの使い方、その王道は、うっすらとしたもの(関係性など)を見つけたい、というところにあると考えるのであれば、検証にビッグデータ的なアプローチをすることは、あまり賢いとはいえないでしょう。ビッグデータから、確かな部分だけを抽出して使う、というアプローチにするべきです。
データから何かを見つけたい場合、たとえば物理、特に素粒子の分野などでは、すでに「このような現象が観測されるはずだ」という理論的なモデルが構築されている場合が多いです。このような場合、データ処理の多くは「パターンマッチング」になります。パターンマッチングは、データの中に、このようなものはあるか、あるならその場所を見つけるというデータ処理です。ゲノム配列から、遺伝子の特徴となる配列を見つけるとか、素粒子の衝突イベントのデータから、特定の素粒子が作る軌跡を抽出するとか、そのようなタスクに使われます。この場合、理論から導かれる「パターン」をどのように定義するか、というモデル構築の部分と、それをデータからいかに高速に見つけ出すか、という計算アルゴリズムのデザインの部分が鍵になります。研究上注力するのは、この2つの部分で十分と言うことになります。だいたい、このような実験の場合、データが大量に出てくるもので、検査したデータを捨てて良いか、という問題が出てくるのですが、これについては下で述べます。
データから見つけたいものが何かわからない場合、データ解析のタスクはマイニングになります。見つけたいものが何かわからない、というのは不思議に感じるかもしれませんが、「この植物種のみに特徴なものが知りたい」「10万ある銀河のデータをいくつかに分類したい」「この遺伝子があるとこういうタンパクができる、というルールが知りたい」など、見つけたいものがなく、見つけたい事柄のみがある、という場合はたくさんあります。これは、データからある種の「仮説」を見つけたい、というものです。古来の研究では、仮説は知識や観察、実験から得られてきました。つまり、人間の思考に大きく頼っていたわけです。ここをある程度自動化し、仮説になりそうな特徴的なもの、ルールや構造や性質などを、いくつも見つけることで仮説を見つけやすくしよう、というのがこのデータ解析の目標になります。目標が比較的あいまいなので、正確性よりは、見つけそこないがない(網羅性)ことや、見つけたものをどうやって評価するか、評価方法が重要になります。
学術研究目的の場合、データ解析の目的は主にこの2つになります。これ以外にも、実験計画の最適化や、観測した事象の定量化(画像に点が何個あるか、とか、虫の羽の大きさを測る、とか)、画像認識、テキスト解析などがありますが、これらはデータ解析というよりも研究に伴うオペレーションの改善が目的になり、使用する技術もデータ解析より、統計や最適化、画像認識、アルゴリズムやデータベースが主となります。ここでは、データ解析の解説を主としていますので、これらの解説は他の機会に譲ることにします。ただ、データの保存に関してだけは、解析と大きく関わるので以下で解説いたします。
天体望遠鏡、粒子加速器、ゲノムシークエンス、監視カメラの映像など、近年は超巨大なデータが学際分野の様々なところで見られるようになりました。これらのデータは学術的に意義深いことが多く、データをすべて保存できればそれにこしたことはないのですが、通常はためることさえ不可能なほど巨大であり、多くの場合は一次的な処理をしたあとにすべて破棄されています。実験データのようなもう一度やり直しができるものであれば良いのですが、天候や宇宙、人の動きや検索ログのような観測データは、過去のデータを取り直すことができません。このようなデータは、長い間蓄積されているだけでも大きな価値を生みますし、すぐに作ろうと思っても作れるものではありません。
その一方で、巨大なデータはそもそも保存すること自体に多大なコストがかかります。持続可能な保存方法を考えるためには、データのスリム化が必要です。単になんらかの圧縮アルゴリズムを使ってコンパクトにできれば良いのですが、巨大なデータの場合、100分の1、あるいは1000分の1にしないとどうにもならない、というようなこともあります。上手に圧縮できても高々1/10程度、このような場合には何かを捨てなければなりません。すべて保存することができないので、すべてを捨てている、というのをよく見かけますが、たとえ少しであっても、それなりに役に立つ部分だけでも継続的に保存すれば、将来大きな役に立つ可能性が残ります。
データの中で、使い道のない無駄な部分はどこか。将来何に使うかわからないのに、それを決めるのは難しいものです。しかし、よくよく考えれば、明らかにいらないだろう、と思われるところは、意外とあるものです。たとえば監視カメラの映像。同じところを撮影しているので、背景は基本的に同じものです。天候によって明るさや影の向きがかわり、植栽が風に揺れますが、背景としては同じで、あまり意味を持ちそうにありません。動いている物体の部分のみを記録すれば良さそうです。動いているもの、あるいはいつもとは異なるものが移っているかどうかは、毎日の画像を平均し(明るさごとに分類するといいでしょう)、平均から大きく離れた画像がある場所のみを抽出すれば良いでしょう。動くもの、映り込むものを特定するのは難しいですが、いつもと違うものだけ、と考えれば、このように意味のありそうな部分だけを保存できます。
宇宙の観測データのようなものは、動きがありません。が、星のないまっくらな部分に関しては、消してしまってもかまわないでしょう。検索ワードを記録するときも、頻度がある程度以上の検索ワード、あるいは頻出するワードの組合せだけを残して、残りのマイナーなものは捨ててしまいます。だいたいの解析では、ある程度以上起こっている現象に興味があり、細かいところまで調べたらきりがないので、こういったマイナーなものは消去してしまっても将来困ったことになることは少ないでしょう。宇宙の写真の中に占める、星の割合はほんの少しです。検索ワードも、メジャーなものだけを残し、その回数だけを覚えておけば、大量のデータを保存する必要はなくなります。このようにすれば、利用価値をあまり減じることなく、データを大幅に削減できます。
なんにしても、このような、データを集め、保存し、課題を考え、解析し、利用する。この一連の流れを上手に行うためには、多様な視点、考え方、技術の俯瞰などが重要です。データ解析や計算など、情報技術に詳しい人に相談してみるのも、良いアプローチの一つと思います。研究はいい課題が見つかれば半分できたも同じ、という言葉にもあるとおり、最初に研究の流れを設計する部分は、研究の中でも特に重要です。データを持っている研究者が情報の研究者とタッグを組むとき、まず研究課題を決めてから相談を持ちかけることが多いですが、むしろ課題を設定する前に相談をした方が、センスがいい、労力がかからずいい結果が導き出せる課題設定ができるに違いない、というのが私の考えです。