9. IPSJ SIG-SLP Corpora and Environments for Noisy Speech Recognition
9-c. Audio-Visual Speech Recognition Evaluation Environment (CENSREC-1-AV)
Data DOI
https://doi.org/10.32130/src.CENSREC-1-AV
Producer, Project
Noisy Speech Recognition Evaluation Working Group,
Special Interest Group on Spoken Language Information Processing,
Information Processing Society of Japan (IPSJ)
Contents
Common platform for evaluating independently speech recognition accuracy and speech interval detection under noisy environment.
An evaluation corpus for audio-visual speech recognition of continuously spoken single digits in Japanese.
The digit sequence of each utterance and the pronunciation of Japanese digits are the same as the CENSREC-1 (AURORA-2J) database.
Including color and infrared mouth images, which were recorded simultaneously with speech.
- Training data
- Clean audio and visual data in an office environment
- Test data
- Clean audio and visual data in the office environment
- Noisy data generated by baseline scripts
- Audio:
- added two types of noise, driving on city streets and driving on expressway, at six different SNR levels
- Image:
- simulated driving conditions using Gamma transform
Speaker
- Training data:
- 42 speakers (22 males, 20 females) 3234 utterances in total
- Test data:
- 51 speakers (25 males, 26 females) 1963 utterances in total
Speech and image file format
- Audio:
- WAV format (16kHz, 16bit, Mono)
- Image:
- Windows BMP format; 24-bit RGB (color), 8-bit grayscale (infrared)
Distribution media
2 DVDs
Licensing
For research and development purposes only
Price
No fee
Image sample
Digit strings same as CENSREC-1
Color and infrared mouth images recorded simultaneously with speech
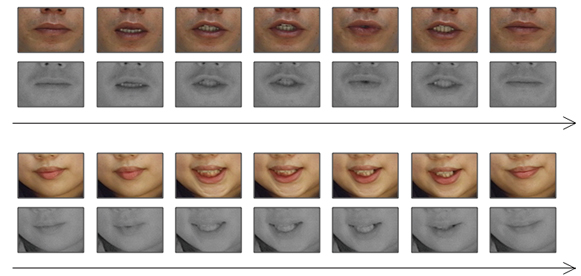
Examples of color and infrared pictures (3 frame/sec, upper: color, lower: infrared)